Token-based Replay Conformance Checking이란 말 그대로 토큰을 이용하여 이를 프로세스 모델에 replay하면서 모델의 conformance를 checking하는 것을 말한다. 이번 포스팅에서는 token-based conformance checking이 무엇인지에 대해 알아보겠다.
Token의 four counters

Token-based Replay Conformance Checking에서 Token은 기본적으로 네 가지의 상태를 가진다. Produced, Consumed, Missing, Remaining이 그것이다. 여기에서 잘 이해가 되지 않으면, 아래의 예시와 함께 하는 부분을 보면 이해가 더 잘 될 것이다.
Produced Token
Produced Token은 앞 transition에서 만들어져서(produced) place로 들어오는 token을 의미한다.
Consumed Token
Consumed Token은 해당 place에 있다가 다음 transition에서 사용되는(consumed) token을 의미한다.
Missing Token
Missing Token은 해당 place에 없었는데(missing) 다음 transition에 의해 사용되어야 하는 token을 의미한다.
Remaining Token
Remaining Token은 해당 place에 produced 되었지만 다음 transition에서 사용되지 않아 남은 (remaining) token을 의미한다.
여기서 Missing과 Remaining 토큰의 수는 적을 수록 좋을 것이다. Missing Token이 많다는 것은 이벤트 로그에 의하면 토큰이 그 자리에 있었어야 했는데 없는 것이고, Remaining Token이 많다는 것은 이벤트 로그에 의하면 사용되지 않아야 하는데 만들어진 것이기 때문에 모두 모델과 이벤트 로그가 일치하지 않는다는 것을 의미하기 때문이다.
Token-based Replay Conformance Checking
이제 실제 모델과 이벤트 로그의 예시와 함께 Token-based Replay Conformance Checking을 어떻게 하는지에 대해 알아보겠다.


위 그림과 같은 예시 페트리 넷과 trace가 있다고 하자. 맨 처음에는 p, c, m, r이 0으로 시작한다. 여기에서 start place에 토큰이 하나 만들어져 있기 때문에 p = 1이 된다. 이제 trace를 모델 위에 올려서 하나하나 따라 간다고 생각하면 된다.

1. 액티비티 a
우리의 trace에서 첫 번째 액티비티 a가 일어났다. 그러면 start에 있던 token이 하나 사라지고 (consumed=1), p1과 p2에 각각 하나씩 token이 만들어질 (produced=2) 것이다. 그러면 p = 1+2 = 3, c = 0+1 = 1, m = 0, r = 0이 된다.

2. 액티비티 c
trace t에서 다음 액티비티는 c이다. 그러면 p1의 token이 하나 사라지고 (consumed = 1), p3에 token이 하나 만들어질 (produced = 1) 것이다. 그러면 p = 3+1 = 4, c = 1+1 = 2, m = 0, r = 0이 된다.
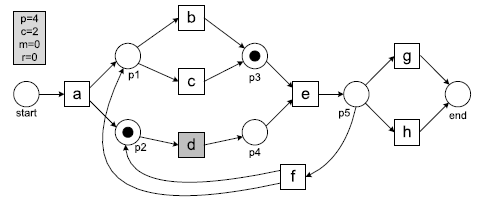
3. 액티비티 d
다음 액티비티는 d이다. 그러면 p2의 token이 하나 사라지고 (consumed = 1), p4에 token이 하나 만들어질 (produced = 1) 것이다. 그러면 p = 4 + 1 = 5, c = 2 + 1 = 3, m = 0, r = 0이 된다.

4. 액티비티 e
다음 액티비티는 e이다. 그러면 p3과 p4의 token이 각각 하나씩 사라지고 (consumed = 2), p5에 token이 하나 만들어질 (produced = 1) 것이다. 그러면 p = 5 + 1 = 6, c = 3 + 2 = 5, m = 0, r = 0이 된다.

5. 액티비티 h
다음 액티비티는 h이다. 그러면 p5의 token이 하나 사라지고 (consumed = 1), end에 token이 하나 만들어질 (produced = 1) 것이다. 그러면 p = 6 + 1 = 7, c = 5 + 1 = 6, m = 0, r = 0이 된다. 여기서 end가 마지막 place이기 때문에 token이 하나 사라지고(consumed = 1), 최종적으로 p = 7, c = 6 + 1 = 7, m = 0, r = 0이 된다.

이렇게 하나의 trace에 대해서 p, c, m, r을 모두 구했다. 이제 다음 식을 이용해서 fitness를 구한다. 이 식이 의미하는 것은, consumed된 것 중에 missing이 아닌 정상적으로 있었던 token과 produced된 것 중에 remained되지 않고 정상적으로 만들어진 token의 비율을 구하는 것이다. 즉, missing과 remained의 숫자가 적을 수록 fitness가 높다고 할 수 있다.

우리의 trace를 이 식에 대입시키면 fitness가 1이 나온다. trace가 모델에 완벽하게 맞아 들었다는 것을 의미한다. 완벽하게 맞지 않는 예시를 하나 더 들어서 설명하도록 하겠다. 위에서 완벽하게 이해했다면 넘어가도 좋다. 다음과 같은 페트리 넷과 trace가 있다고 하자.


아까와 똑같이 맨 처음에는 p, c, m, r이 0으로 시작한다. 여기에서 start place에 토큰이 하나 만들어져 있기 때문에 p = 1이 된다. 또 다시 trace를 모델 위에 올려서 하나하나 따라 간다고 생각하면 된다.

1. 액티비티 a
우리의 trace에서 첫 번째 액티비티 a가 일어났다. 그러면 start에 있던 token이 하나 사라지고 (consumed=1), p1에 token이 하나 만들어질 (produced=1) 것이다. 그러면 p = 1+1 = 2, c = 0+1 = 1, m = 0, r = 0이 된다.

2. 액티비티 d
다음 액티비티는 d이다. 그런데 d 액티비티가 일어나려면 p2에 token이 하나 있어야 하는데 존재하지 않는다. 이것이 바로 missing token이다. 그러므로 missing = 1이 되고, 이 token이 사용되고 (consumed = 1), p3에 token이 하나 만들어질 (produced=1) 것이다. 그러면 p = 2 + 1 = 3, c = 1 + 1 = 2, m = 0 + 1 = 1, r = 0이 된다.

3. 액티비티 c
다음 액티비티는 c이다. 그러면 p1의 token이 하나 사라지고 (consumed = 1), p2에 token이 하나 만들어질 (produced = 1) 것이다. 그러면 p = 3 + 1 = 4, c = 2 + 1 = 3, m = 1, r = 0이 된다.

4. 액티비티 e
다음 액티비티는 e이다. 그러면 p3의 token이 하나 사라지고 (consumed = 1), p4에 token이 하나 만들어질 (produced = 1) 것이다. 그러면 p = 4 + 1 = 5, c = 3 + 1 = 4, m = 1, r = 0이 된다.

5. 액티비티 h
다음 액티비티는 h이다. 그러면 p4의 token이 하나 사라지고 (consumed = 1), end에 token이 하나 만들어질 (produced = 1) 것이다. 그러면 p = 5 + 1 = 6, c = 4 + 1 = 5, m = 1, r = 0이 된다. 여기서 end가 마지막 place이기 때문에 token이 하나 사라지고(consumed = 1), p2에 token이 하나 남아 있기 때문에 (remaining = 1) 최종적으로 p = 6, c = 5 + 1 = 6, m = 1, r = 0 + 1 = 1이 된다.

이를 다시 fitness 식에 넣어서 계산해 준다.
그러면 값은 5/6이 나온다.
이벤트 로그에 대한 Token-based Replay Conformance Checking
위에서 우리는 각 trace에 대해서 p, c, m, r을 계산하여 fitness를 구하는 방법을 알아 보았다. 그러면 여러 개의 trace가 섞여 있는 이벤트 로그에 대해서는 이를 어떻게 계산해야 할까? 답은 간단하다. 다음 식에 각 값을 넣으면 된다.

무섭게 생겼지만 그냥 귀여운 친구일 뿐이다. 각 trace에 대해 p, c, m, r을 계산한 후 각 trace들의 수만큼을 곱해서 모두 더하면 된다. 간단히 예를 들어보겠다. 아래와 같은 event log와 페트리넷이 있다고 하자.


각 trace들에 대해서 위에서 한 방법으로 p, c, m, r을 구하면 다음과 같은 결과가 나온다. (과정은 생략하겠다.) 이들을 각각의 frequency로 곱해주면 아래 표의 주황색 부분의 숫자가 나온다.

각 p, c, m, r을 더해주면 p = 60 + 60 + 60 + 10 + 5 + 4 + 6 = 205, c = 60 + 60 + 60 + 10 + 5 + 4 + 6 = 205, r = 2 + 1 + 2 + 2 = 7, m = 2 + 1 + 2 + 2 = 7이 된다. 이를 위의 식의 각 자리에 넣어주면 된다.
그러면 198/205라는 fitness 값을 얻을 수 있다. 위 로그 L의 fitness = 198/205 = 0.9658이 되는 것이다.
Token-baed Replay 방식의 한계
Token-based Replay Conformance checking 방식의 한계점에는 무엇이 있을까?
1. 모든 transition이 unique하다고 가정한다.
우선, 이 방식은 모든 transition이 unique하다고 가정한다. 만약 transition의 이름이 같은데 다른 transition이 있다면 어떤 transition을 fire시켜야하는지를 모를 것이고, p, c, m, r도 제대로 계산할 수 없기 때문이다.
2. 너무 낙관적인 결과를 보여 주기도 한다. ( generalization, simplicity, precision을 고려하지 못한다.)
예를 들어, 다음과 같은 flower model이 있다고 하자.

이 모델에 시작 액티비티가 a이고, 끝 액티비티가 g,h인 trace라면 그 사이의 b, c, d, e, f의 순서가 어떻게 된 trace를 replay하든 fitness는 1의 값을 보여준다. 이는 다른 conformance checking 방식들로 도출된 fitness 값이 가지는 공통적인 문제점이기도 하다. (그러므로 generalization, simplicity, precision을 모두 고려해야 한다.)
3. local decision이 반영되어야 하는 모델에 대해서 너무 낙관적인 결과를 보여준다.
local decision이란, 앞에 선행된 액티비티가 뒤의 액티비티의 행동을 결정하는 것을 의미한다. 다음 예시를 보자.

위 페트리 넷은, a 액티비티가 실행될 경우에 d1, d2, d3가, b 액티비티가 실행될 경우에 e1, e2, e3가 실행되어야 한다는 local decision이 반영되어 있는 모델이다. 하지만 만약 <a, c1, c2, e1, e2, e3>라는 trace가 있을 때 이를 token-based replay conformance checking을 해 보면 (과정은 생략한다.) p = 8, c = 8, m = 1 , r = 1의 결과로 fitness가 0.875로 비교적 높은 결과가 나온다. 하지만 위 trace는 local dependency가 고려되지 못한 완전히 틀린 trace이다. 즉, 이렇게 local dependency가 있는 경우에는 과하게 낙관적인 fitness가 나오는 것이다.
Token Based Replay Conformance Chekcing은 이렇게 몇 몇 한계점도 있지만, token을 trace에 따라 모델 위에 하나하나 replay 해 가면서 conformance를 checking하고, 이에 따라 frequency도 고려할 수 있기 때문에 장점 또한 존재하는 conformance checking 방식이다.
References
1. Section 8.2. of Wil van der Aalst. Process Mining: Data Science in Action (Second Edition) : Springer, 2016.
2. Course: Business Process Intelligence. Prof. Wil M.P. van der Aalst. RWTH








최근댓글