Random Forest는 Decision Tree들을 엮어서 Forest를 만듦으로써 더 좋은 예측을 하게 만드는 분류 기법의 하나이다. Random Forest는 Support Vector Machine, Boosting 등과 함께 아주 좋은 예측 성능을 가지는 머신 러닝 기법 중 하나이다. 이번 포스팅에서는 이 Random Forest가 무엇이고, 어떻게 만들어지는지에 대해 알아보겠다.
Motivation
예를 들어, 다음과 같은 스테인드 글라스가 있다고 하자. (뜬금)
우리는 이 세 개의 스테인드 글라스의 각 칸에 대해 다음과 같이 각각 원하는 색의 진하기로 색을 칠할 것이다.

그런데 이 상황에서 이들을 바탕으로 해서 특정 부분을 딱 집으면 내가 그 부분에 대해서 어떤 색을 칠하기 싶은지를 예측한다고 하자. 만약 이들을 합한다면, 다음과 같은 그림이 될 것이다.
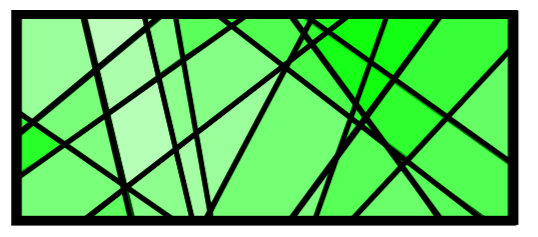
이들을 합함으로써 특정 부분에 대해 내가 어떤 색을 칠하고 싶은지에 대해 더 쉽게 알 수 있을 것이다. Random Forest는 이와 같은 아이디어를 기반으로 한다.
형성 과정
그럼 이제 본격적으로 Random Forest를 어떻게 만드는지에 대해 알아보겠다.
1. 많은 Decision Tree들을 만든다.
Decision Tree가 엮여서 만들어지는 Random Forest를 만들기 위해서는 당연히 Decision Tree가 필요하다. 이를 위해 우선, 50-1000개 정도의 많은 Decision Tree들을 만든다. 하지만 이들이 모두 같은 모양을 가지고 있다면 이는 아무 의미가 없을 것이다. 그렇다면 이들을 어떻게 다르게 만들 수 있을까?
2. Inject randomness into trees
각각의 Decision Tree들을 다르게 만드는 방법이 여기에서 등장한다. 이에는 여러 가지 방법들이 있을 수 있지만, 두 개의 방법을 소개하려고 한다.
- Bootstrap sampling process: 단순히 N개의 training example들에 대해 이들을 N번 random하게 뽑음으로써 training set을 선택하는 것을 말한다. 이 때, 이 뽑기는 replacement를 허용한다. 즉, 뽑은 example을 또 뽑을 수도 있는 것이다.
- Random attribute selection: 각 node들을 만들 때, 모든 attribute를 사용하는 것이 아니라 그 중 일부만 사용하는 것을 말한다. 이 때, 이 수는 정하기 나름이지만 보통은 원래의 attribute 수의 제곱근을 사용한다. 이를 통해 더 빠르게 decision tree를 만들어냄과 동시에 각 tree 간의 correlation도 낮출 수 있다.
3. Ensemble
이제 1과 2에서 도출해 낸 tree들의 결과를 합해 Forest를 만들 차례이다. 이에는 기본적으로 voting을 사용한다. (다른 방법도 가능하다.) 즉, 같은 데이터를 위에서 도출한 decision tree들에 넣었을 때, 가장 많은 표를 받은 결과값을 우리의 random forest의 결과값으로 채택하는 것이다. 예를 들어, 다음과 같은 세 개의 decision tree가 있다고 하자.
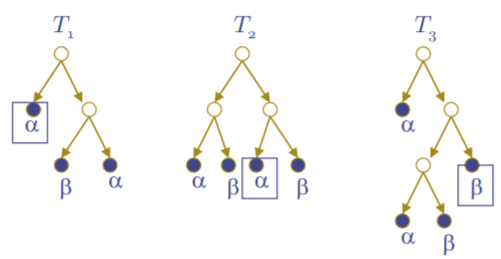
이들에 우리의 input data를 넣었을 때, 표시된대로 T1에서는 a, T2에서는 a, T3에서는 b의 결과가 나왔다고 하자. 그러면 우리는 더 많은 표를 얻은 a를 우리의 random forest 결과값으로 채택하는 것이다.
장점과 단점
장점
- 알고리즘이 굉장히 간단하다. Decision Tree를 어떻게 만드는지만 알고 있다면, 이들의 결과를 단순히 voting 등을 통해 종합하기만 하면 되기 때문에 굉장히 쉽게 이해하고 구현할 수 있다.
- Overfitting이 잘 되지 않는다. 새로운 데이터에 대해 굉장히 잘 generalize되는 편이다.
- Training이 빠르다.
단점
- Memory 사용량이 굉장히 많다. Decision Tree를 만드는 것 자체가 memory를 많이 사용하는데, 이들을 여러 개 만들어 종합해야 하기 때문에 memory consumption이 많다.
- training data의 양이 증가해도 급격한 성능의 향상이 일어나지 않는다.
이번 포스팅에서는 Random Forest가 무엇이고, 이를 어떻게 형성할 수 있는지에 대해 알아보았다.
References
Machine Learning. Prof. Bastian Leibe. RWTH. 2019.








최근댓글