Decision Tree는 tree 구조를 활용하여 entropy가 최소화되는 방향으로 데이터를 분류하거나 원하는 어떤 결과값을 예측하는 분석 방법을 말한다. 이번 포스팅에서는 Decision Tree가 무엇이고, 이를 어떻게 만들 수 있는지를 알아보겠다.
Decision Tree란?
Decision Tree란, 위에서도 말했듯이 데이터를 이용하여 이를 분류하거나 결과값을 예측하는 분석 방법을 말한다. 결과 모델이 Tree 구조를 가지고 있기 때문에 Decision Tree라는 이름을 가진다. 그림을 보면 더 쉽게 이해가 가능하다.
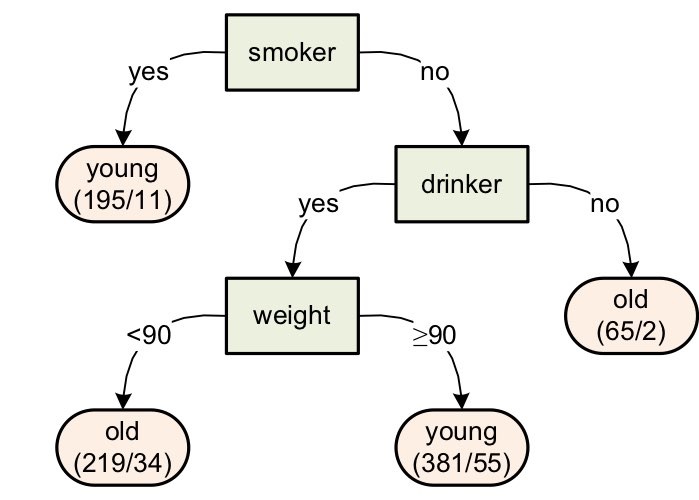
이 decision tree는 나이를 예측하는 decision tree이다. 그림을 해석하면 다음과 같다. 담배를 피는 사람 (smoker - yes)이라면 나이가 어리다. 왜냐하면, 담배를 피는 사람 (smoker - yes) 195명 중에서 184명이 young이고 11명만이 old이기 때문이다. 담배를 피지 않는 사람 (smoker - no) 중에서 술을 마시지 않는 사람 (drinker - no)은 나이가 많다. 왜냐하면, 담배를 피지 않고 술을 마시지 않는 사람 65명 중에서 2명만이 young이고 63명이 old이기 때문이다.
Decision Tree에서 맨 처음으로 갈라지는 곳 (우리의 예시에서는 smoker)을 root node, 중간에서 갈라지는 곳 (drinker, weight)을 intermediate node, 맨 끝 부분 (young / old)을 terminal node라고 부른다.
Decision Tree의 기본 아이디어
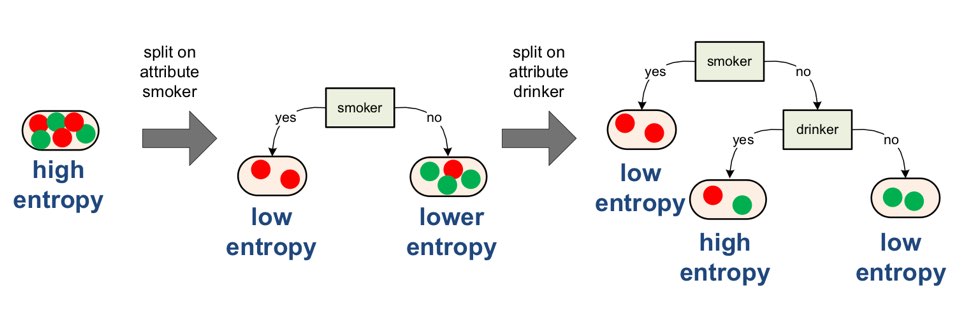
Decision Tree의 기본 아이디어는 terminal node가 가장 섞이지 않은 상태로 완전히 분류되는 것, 즉 복잡성(entropy)이 낮도록 만드는 것이다. 예를 들어, 맨 처음에 이렇게 모두 섞인 데이터가 있다고 하자.

이를 특정 기준으로 나누면 각 나눠진 부분집합의 entropy를 현재보다 더 낮게 만들 수 있을 것이다.

하지만 smoker = no로 분류된 subset은 아직 완벽하게 분류가 되지 않았다. 그렇기 때문에 이에 대해 다른 기준으로 분기를 한 번 더 진행한다.

이런 식으로 나눠진 각 subset (terminal node)의 복잡성이 가장 낮은 방향으로, 즉 가장 덜 섞인 방향으로 decision tree를 발전시켜 나가는 것이 decision tree의 목적이다.
기본적인 개념
Impurity
Impurity란, 말 그대로 복잡성을 말한다. 즉, 해당 노드 안에서 섞여 있는 정도가 높을수록 복잡성이 높고, 덜 섞여 있을수록 복잡성이 낮다. 이 Impurity를 측정하는 척도에는 다양한 종류가 있는데, 오늘은 Entropy에 대해서만 소개하도록 하겠다. Entropy는 아래와 같은 식으로 계산할 수 있다.

예를 들어, 다음과 같은 노드가 있다고 하자.

이 노드에는 전체 6개의 원 중 3개는 빨간색, 3개는 초록색으로 이루어져 있다. 이 노드의 entropy를 계산하면 다음과 같다.
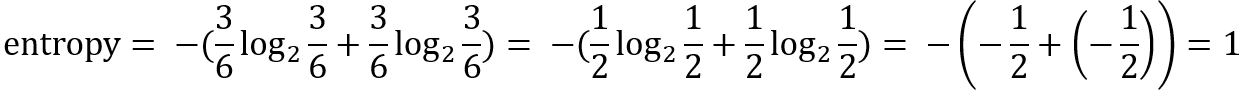
Information Gain
Information Gain이란, Decision tree에 의해 나누어 진 subset의 entropy - 나누기 전의 entropy 값을 의미한다. 즉, decision tree에 의해 split됨으로써 데이터가 덜 복잡해지는 정도를 말한다. Information Gain이 높을수록 split의 성능이 좋은 것이고, 낮을수록 split의 성능이 좋지 못한 것이다.
Decision Tree 만드는 법
1. 데이터에서 예측할 값(종속 변수. response variable)과 이를 예측하기 위해 사용하는 값(독립 변수. predictor variable)을 선택한다.
예를 들어, 다음과 같은 데이터가 있다고 하자.
| 이름 | 요리를 좋아하는가? | 지난 주말에 집에 있었는가? | 내향적 / 외향적 |
| Y | yes | yes | 외향적 |
| H | yes | yes | 외향적 |
| S | no | yes | 외향적 |
| D | no | yes | 내향적 |
| W | no | no | 내향적 |
| K | yes | no | 외향적 |
| G | no | no | 외향적 |
| M | no | yes | 외향적 |
이 데이터 중 요리를 좋아하는지의 여부, 지난 주말에 집에 있었는지의 여부를 이용해 사람의 내향성/외향성을 판별하는 decision tree를 만들고 싶다고 하자. 그러면 종속 변수로는 요리를 좋아하는가, 지난 주말에 집에 있었는가가 독립 변수, 내향성/외향성이 종속 변수가 된다.
2. 모든 독립 변수들에 대해서 가장 information gain을 높게 만드는 독립 변수를 찾는다.
우선, split하기 전의 데이터의 entropy를 계산한다. 총 8개의 데이터 중 외향적이 6개, 내향적이 2개이기 때문에 entropy는 다음과 같다.

우리의 예시에서는 독립 변수가 두 개 있다. 먼저, 요리를 좋아하는가?에 따른 entropy를 계산해보자. 우선, 요리를 좋아하는가에 따라 decision tree를 만들면 다음과 같은 형태가 된다.

이에 대해 각 노드에 대한 entropy를 계산하면 다음과 같다.

그러므로 해당 split에 대한 entropy를 계산하면 다음과 같다.

그러므로 이에 대한 information gain은 0.815 - 0.6075 = 0.2075이다.
다음으로, 저번 주말에 집에 있었는가? 에 따른 entropy를 계산해보자. 우선, 저번 주말에 집에 있었는가에 따라 decision tree를 만들면 다음과 같은 형태가 된다.

이에 대해 각 노드에 대한 entropy를 계산하면 다음과 같다.

그러므로 해당 split에 대한 entropy를 계산하면 다음과 같다.

그러므로 이에 대한 information gain은 0.815 - 0.796 = 0.019이다.
Information gain이 더 높은 기준이 요리를 좋아하는가? 이기 때문에 이에 의해서 decision tree를 만든다.
3. 2의 과정을 더 이상 일정 이상의 information gain이 없을 때까지 (혹은 다른 threshold를 만족할 때까지) 반복한다.
information gain의 최솟값을 정해놓지 않으면 독립 변수가 많은 경우 decision tree가 너무 깊게 만들어질 수도 있고, verfitting의 위험도 있다. 그렇기 때문에 이를 threshold로 정해 놓아야 한다. 이외에도 maximal depth, minimal size of node 등이 threshold가 될 수 있다.
우리의 information gain threshold를 0.1이라고 하자. 요리를 좋아하는가?의 decision tree에서 오른쪽 node는 아직 entropy가 0이 아니기 때문에 information gain이 있을 수 있다. 이에 대해 다른 독립변수를 이용해 한 번 더 split을 해 본다.

이에 대해 각 노드에 대한 entropy를 계산하면 다음과 같다.

그러므로 해당 split에 대한 entropy를 계산하면 다음과 같다.

이에 따른 information gain은 0.6075 - 0.5958 = 0.0117이다. 우리의 threshold인 0.1보다 information gain이 작기 때문에 이 split은 진행하지 않는다.
4. 결과 decistion tree가 완성되었다.
이번 포스팅에서는 Decision Tree가 무엇이고 이를 어떻게 만들 수 있는지에 대해 알아보았다. 다음 포스팅에서는 Decision Tree의 다양한 Impurity 지표 (Entropy, GINI index, GR)에는 무엇이 있는지, 그리고 Decision Tree와 프로세스 마이닝이 어떻게 연관되어 있는지를 알아보겠다.








최근댓글