Confusion Matrix는 Classification 결과의 성능을 분석하는 가장 기본적인 척도로, 정말 간단하게 행렬 형태로 몇 개의 데이터를 어떤 분류로 분류했는지를 보여줌으로써 분류 예측의 성능을 알려준다. 이번 포스팅에서는 RapidMiner로 Confusion Matrix를 도출하는 방법에 대해 알아보겠다.
1. Classification Model을 만든다.
모델의 classification 성능을 분석하려면, 우선 성능을 분석할 대상이 되는 모델이 있어야할 것이다. 그러므로 Classification model을 준비한다. (이 포스팅에서는 저번 RapidMiner로 Decision Tree 분석하기에서 사용한 decision tree 모델을 사용하도록 하겠다.)

2. Performance operator를 선택해준다.
모델의 성능을 분석하기 위한 performance operator를 선택한다. 이 글에서 사용된 데이터는 binomial classification이기 때문에 Performance (Binomial Classification) operator를 선택하였다.

3. Apply Model operator를 선택해준다.
Performance operator에는 모델 자체가 바로 input으로 사용될 수 없다. 그렇기 때문에 Apply Model operator를 이용하여 performance operator의 input으로 사용될 수 있도록 한다.

Apply Model의 mod input에 Decision Tree의 mod를, uni input에 Decision Tree의 exa를 연결해주고, Performance의 lab과 Apply Model의 lab을 연결해준다. 마지막으로, 결과 확인을 위해 Performance의 per과 res(output)을 연결한다.
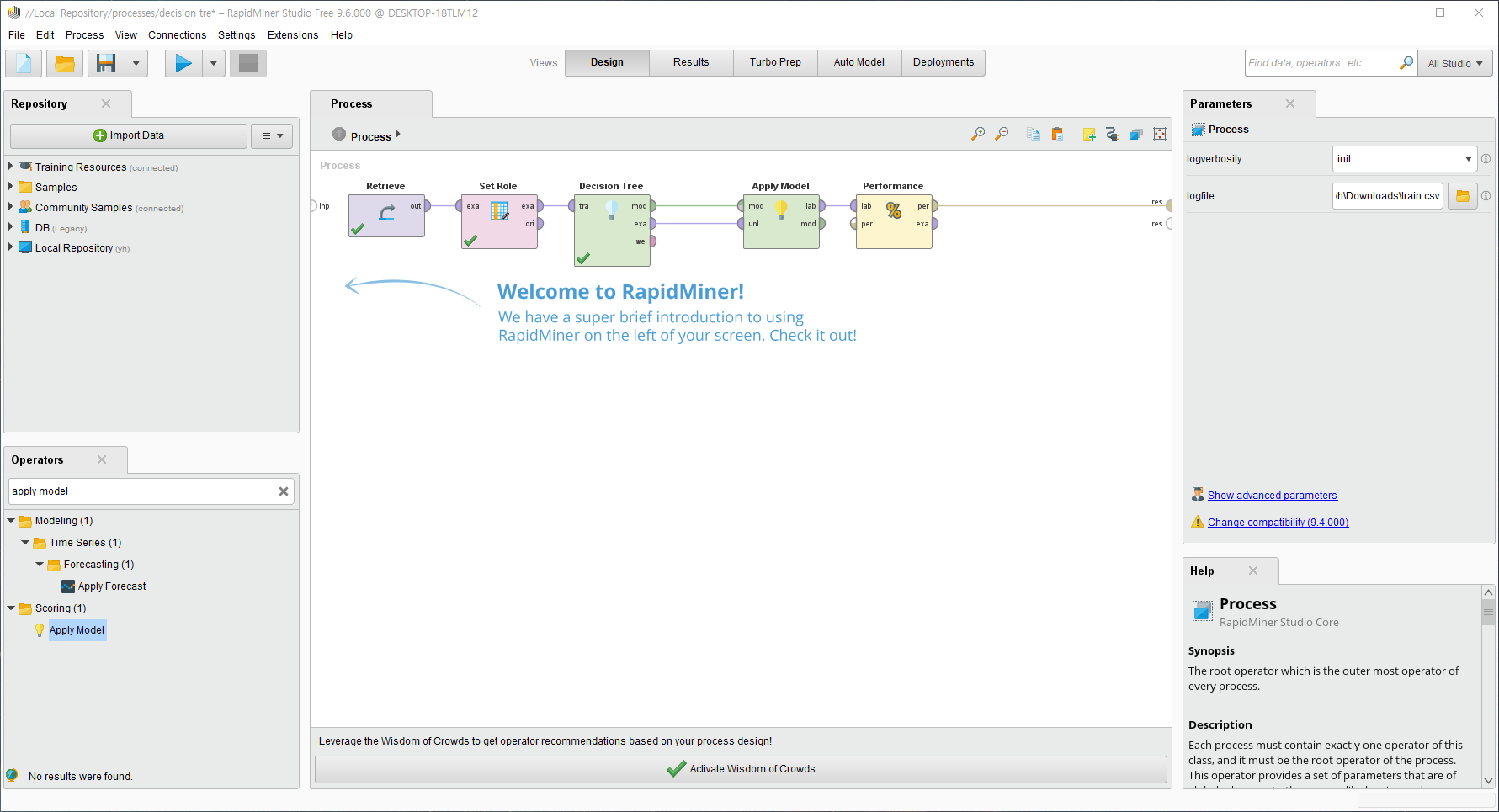
4. 재생 버튼을 눌러 Confusion Matrix를 확인한다.
왼쪽 상단의 재생 버튼을 눌러 Confusion Matrix를 확인할 수 있다.

이번 포스팅에서는 RapidMiner에서 Confusion Matrix를 도출하는 방법에 대해 알아보았다. Classification 문제에 있어 가장 기본이 되는 성능 지표이기 때문에, 여러 방법으로 활용될 수 있을 것이다.







최근댓글