프로세스 마이닝을 할 때 기본적으로 이용되는 데이터인 이벤트 로그는 Case ID, Activity, Timestamp 정보를 필수적으로 가진다. 이 중 Case ID는 하나의 케이스끼리 공유하는 key 값으로 프로세스마이닝에는 없어서는 안 될 존재이지만, 실제 데이터에서 Case ID가 명확히 명시되어 있지 않은 경우가 많다. Correlation Mining은 이렇게 Case ID가 없는 경우에도 프로세스 마이닝이 가능하게 만들어준다. 이번 포스팅에서는 Correlation Mining이 무엇인지에 대해 알아보겠다.
알고리즘
Correlation Mining 알고리즘을 설명하기 위해 예시 이벤트 로그를 하나 가져오겠다.

이 예시 이벤트 로그로부터 도출될 모델은 다음과 같은 형태로 표현될 수 있을 것이다.
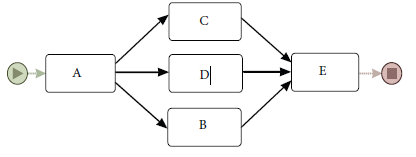
(논문에서는 해당 형태의 프로세스 모델을 Orchestration Model이라고 부르는데, 빈도가 표현된 DFG의 형태와 유사하므로 해당 모델에 대해 따로 설명하지 않겠다.)
Correlation Mining 알고리즘은 두 개의 Matrix를 만들고, 이로부터 가능한 모든 모델을 도출한 후 가장 성능이 좋은 모델을 선택하는 과정으로 이루어진다. 이 과정들을 하나하나 살펴보도록 하겠다. 우선, 첫 번째 단계인 두 개의 Matrix를 생성하는 것부터 살펴보자. 이 두 개의 Matrix는 Precede/Succeed matrix와 Duration matrix이다.
Precede/Succeed matrix
Precede/Succeed matrix는 쉽게 말하면 각 액티비티들이 서로 선행/후행될 확률을 표현한 행렬이다. 즉, 각 액티비티들이 행과 열이 되고, 그 성분은 액티비티 i로 시작한 이벤트 중 후에 액티비티 j를 수행하는 비율을 표현한다. 이를 식으로 표현하면 다음과 같다.

위 식에서 분모 부분은 액티비티 i가 일어난 이벤트 개수 * 액티비티 j가 일어난 이벤트 개수를 말한다. 분자는 각 이벤트 쌍 (i 액티비티인 이벤트, j 액티비티인 이벤트)들 중 j 액티비티가 i 액티비티보다 늦게 일어난 횟수를 말한다. 예시를 통해 설명해보겠다. 우리의 예시 이벤트 로그를 다시 살펴보자.
여기서 우리가 P/S_(C,E) 값을 구하고 싶다고 하자. 액티비티 C의 이벤트 개수는 case 6, 7, 10에서 각각 한 번씩으로 총 3개이고, 액티비티 E의 이벤트 개수는 모든 케이스에서 일어났으므로 10이다. 그러므로 분모는 30이 된다. 다음으로, 각 pair에 대해서 C가 E보다 일찍 일어난 모든 쌍(예: 6의 C가 07:08에 일어났고, 9의 E가 10:20에 일어났으므로 이들은 이에 포함된다.)을 구하면 17개가 된다. 그러므로 P/S_(C,E) 값은 17/30이 된다. 이런 식으로 모든 값을 다 구해보면 다음과 같은 matrix가 도출된다.

이 값이 낮을수록 해당 선행 액티비티 뒤에 후행 액티비티가 올 확률이 낮아지고, 값이 높을수록 해당 선행 액티비티 뒤에 후행 액티비티가 올 확률이 높아질 것이다.
Duration matrix
다음 순서는 Duration matrix를 도출하는 것이다. Duration matrix는 쉽게 말하면 각 액티비티 사이의 시간(timestamp)차이를 표현한 행렬이다. 이 시간차를 계산하기 위해 우리는 mapping 함수를 하나 정의한다. 그 mapping 함수의 조건은 다음과 같다.
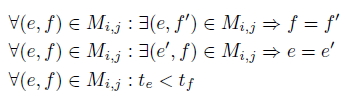
즉, 각 이벤트는 매핑 안에 최대 한 번만 속할 수 있고(일대일 매핑), 선행 액티비티의 이벤트보다 후행 액티비티의 이벤트의 timestamp가 더 뒤에 있어야 한다는 의미이다. 그리고 이 매핑은 다음과 같은 제약 조건 또한 만족해야 한다.

즉, 매핑은 최대한 많이 해야하고, 매핑의 시간차의 분산을 최소화하는 방향으로 매핑이 진행되어야 한다는 것이다. 이는 같은 케이스 안에 있는 이벤트 간의 시간차가 다른 케이스 안에 있는 이벤트 간의 시간차에 비해 훨씬 일정할(분산이 작을) 것이라는 가정으로부터 도출되었다. 예를 들어, 우리가 액티비티 D와 C 사이의 매핑을 구한다고 하자. 그렇다면 아래와 같은 매핑이 가장 많은 매핑을 도출함과 동시에 가장 매핑의 시간차의 분산을 작게 한 것이다.

이렇게 매핑을 하고 나면 해당 M_(i, j)들의 시간차의 평균 혹은 표준편차를 우리의 Duration matrix의 성분으로 사용한다. 그렇데 도출된 Duration matrix는 다음과 같다.

이 duration matrix의 경우 낮을수록 실제로 그 둘 사이에 엣지가 있을 확률이 높다. (하지만 값이 0인 경우에는 둘 사이에 엣지가 있는 경우는 없다.)
Model Construction
이렇게 두 행렬을 도출했다면 이제 프로세스 모델을 도출할 차례이다. 이 과정은 모든 가능한 모델을 도출하고, 그 모델들로부터 최적의 모델을 선택하는 두 가지 과정으로 나누어진다.
가능한 모든 모델 도출
가능한 모든 모델을 도출하는 데에는 ILP(Integer Linear Programming) 개념이 사용된다. 이에 사용되는 변수 x_ij는 액티비티 i와 액티비티 j 사이의 directly follows relation의 빈도이다. 이 때, 위에서 구한 P/S_(i,j)값이 너무 낮거나 D_(i,j)값이 너무 높거나 0인 경우 이를 제외한다. 또한 start activity로 들어가는 x(x_(i, start activity))의 경우나 end activity로부터 나오는 x(x_(end activity, j)) 또한 이를 제외한다. 이를 식으로 표현하면 다음과 같다.

또한 우리는 각 노드로 들어가는 엣지의 개수와 각 노드로부터 나오는 엣지의 개수, 그리고 각 노드의 빈도가 모두 같은 모델을 얻기를 원한다. 그러므로 이를 식으로 표현하면 다음과 같이 표현할 수 있다.

예를 들어, 우리의 예시 이벤트 로그로부터 다양한 제약 조건을 도출한다고 하자. 그렇다면 우리는 이러한 제약 조건들을 도출할 수 있을 것이다.

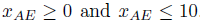
최적의 모델 선택
위의 알고리즘으로부터 도출된 모델은 여러 종류가 도출될 수 있다. 그렇기 때문에 우리는 이들 중 최적의 모델을 선택해야 한다. 위에서 두 행렬을 구할 때, P/S_(i,j) 값이 높고 D_(i,j) 값이 낮을수록 액티비티 i와 j 사이에 엣지가 있을 확률이 높다고 설명했다. 그렇기 때문에 우리는 D_(i,j)/P/S_(i,j) 값이 작을수록 액티비티 i와 j 사이에 엣지가 있을 확률이 높다고 가정할 수 있을 것이다. 그러므로 우리는 우리의 식을 다음과 같이 쓸 수 있을 것이다.

이 때, min(E_i, E_j)의 역수를 곱하는 이유는 해당 엣지의 빈도가 높을수록 엣지가 더 중요하게 생각되는 상황을 방지하기 위해서이다. 이 식을 만족하는 x_ij를 구하면, 우리는 Case ID 없이도 최적의 모델을 도출할 수 있다. 이를 통해 우리의 예시 이벤트 로그로부터 도출되는 프로세스 모델은 다음과 같다.

이번 포스팅에서는 Case ID 없이 프로세스 마이닝을 할 수 있게 해주는 Correlation Mining에 대해 알아보았다. 개인적으로 데이터에 Case ID가 있어야 한다는 점이 프로세스 마이닝의 굉장히 큰 제약으로 여겨졌기 때문에, 이러한 접근은 굉장히 흥미로운 접근이었다.
References
Pourmirza, Shaya, Remco Dijkman, and Paul Grefen. “Correlation miner: mining business process models and event correlations without case identifiers.” International Journal of Cooperative Information Systems 26.02 (2017): 1742002.








최근댓글