Chemical VAE는 어떤 분자 (molecule) 구조를 continuous representation으로 표현하고, 이 continuous representation에 대해 optimization을 통해 최적의 분자 구조를 도출하는 것을 목적으로 한다. 이번 글에서는 graph generative / optimization model 중 하나인 chemical VAE (해당 논문의 github이 chemical VAE라는 이름을 택하고 있어서 이 이름을 사용했다. 논문에는 따로 method를 부르는 이름은 없다.)가 무엇인지에 대해서, Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules 논문을 리뷰하면서 알아보겠다. 첫 generative model 글...
* 이 글은 VAE에 대한 기본적인 이해가 있다고 가정한다.
배경
우선, chemical VAE가 제안된 배경이 무엇인지에 대해 먼저 알아보겠다. Chemical VAE는 위에서 언급한 것처럼 어떤 분자 (molecule) 구조를 continuous representation으로 표현하고, 이 continuous representation에 대해 optimization을 하는 것을 목적으로 한다. 그렇다면 분자 구조를 continous representation으로 표현해야 하는 이유는 무엇일까? 예를 들어, 다음과 같은 SMILES 표기가 있다고 하자.

SMILES 표기는 discrete representation의 대표적 예시이다. 이러한 표기 방식에서 우리가 분자를 optimization하고 싶다면 어떻게 해야할까? 이를 숫자 형식으로 바꾼다 하더라도, 그것의 discrete한 특성은 변함이 없고, 미분을 통한 gradient based optimization 방법은 적용이 불가능할 것이다. 그렇기 때문에 분자 구조를 continuous한 방법으로 표기해야하는 needs가 생겼다.
Approach
Chemical VAE의 방법론을 한 줄로 요약하면 jointly-trained VAE for property optimization이라고 표현할 수 있다. 즉, property optimization을 위해 VAE를 joint하게 학습한다는 의미이다. 이를 그림으로 표현하면 아래와 같다.

즉, 이는 크게 continous representation의 학습을 위한 VAE와, 이 학습된 continous representation을 기반으로 한 optimization의 두 부분으로 나눌 수 있다. 우선 continous representation의 학습을 위한 VAE부터 살펴보겠다.
jointly-trained VAE
jointly-trained VAE는 기존의 단순히 ELBO를 최소화하는 방향으로 generative model을 학습하던 VAE와는 달리, 우리가 optimize하기를 원하는 property의 예측 loss까지 최소화하는 방향으로 VAE를 학습한다.

위 식에서 왼쪽 loss가 VAE의 loss, 오른쪽 loss가 continuous representation을 기반으로 한 property prediction loss이다. VAE를 위 식의 loss가 최소화되는 방향으로 학습하는 것이다. 즉, 우리가 학습하기를 원하는 jointly-trained VAE는 VAE와 property prediction이 결합된 형태라고 할 수 있다.
VAE
jointly-trained VAE의 첫 번째 구성 요소인 VAE는 분자 구조의 continous representaiton을 학습하는 것을 목적으로 한다. 이 때, SMILES를 input으로 받고, 이 input을 reconstruct하는 output을 generate하는 것을 목적으로 하여 encoder과 decoder를 학습하는 것이다. 이 구조는 아래 그림과 같다.
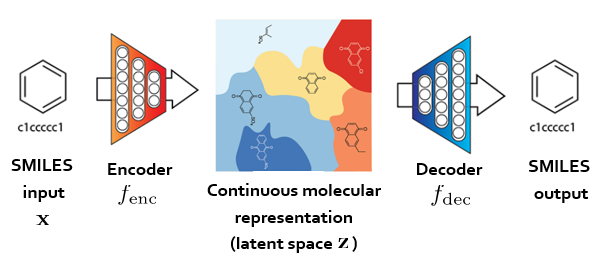
위 구조에서 encoder는 SMILES를 continous molecular representation으로, decoder는 continous molecular representation을 SMILES로 변환하는 역할을 한다. 그 과정에 있는 latent space z가 continous molecular representation의 역할을 하는 것이다.
property prediction
우리의 목적은 위 VAE로부터 도출된 continous representation을 활용해서 어떤 property를 optimize하는 molecule을 도출하는 것이다. 하지만 위 방식으로만 VAE를 학습하게 되면 도출된 latent space가 우리가 원하는 property와 아무 연관이 없게 된다. 그렇기 때문에 이 latent space를 우리가 원하는 property와 연관이 있게 만들기 위해 아래 그림과 같이 latent space로부터 property prediction network를 학습하고, 이 error를 VAE에 동시에 학습시킨다.

VAE의 loss와 property prediction loss를 jointly-trained VAE에 동시에 학습시킴으로써 우리는 분자의 특성과 함께 property를 반영한 continous molecular representation을 얻었다.
property optimization
이제 jointly-trained VAE로부터 얻은 representation을 optimization에 활용할 차례이다. 우리가 continuous한 representation을 얻었기 때문에, gradient-based optimization을 적용할 수 있다. 이는 아래 그림과 같이 표현할 수 있다.

Optimization 단계를 좀 더 자세히 표현하면, 아래와 같다. (Optimization 방법이 gradient descent라고 가정한다.)
- latent vector z를 하나 선택한다.
- desired property를 improve하는 방향으로 이동한다.

3. result vector z를 SMILES로 다시 decode한다.
이 과정을 통해 우리는 우리가 원하는 property를 가지는 molecule을 얻을 수 있다.
Experiment
Chemical VAE가 얼마나 잘 작동하는지를 몇 가지 실험을 통해 알아보겠다.
우선, continuous molecular representation이 분자 구조를 굉장히 잘 표현할 수 있다. 이를 증명하는 실험 결과는 아래와 같다.

이부프로펜(오늘 먹음) 분자가 있다고 할 때, 그것의 latent space에서의 거리가 멀어질수록 완전히 다른 분자 구조를 보임을 알 수 있다. 즉, latent space에서의 거리가 분자 구조의 dissimilarity를 잘 표현한 것이다.
다음으로, VAE가 얼마나 molecule을 잘 generate할 수 있는지에 대한 실험이다. 이를 증명하는 실험 결과는 아래와 같다.

VAE로부터 generate된 molecule들이 logP, 합성가능성 (SAS), drug-likeness (QED) 모든 property에 대해 GA(Genetic Approach)보다 training data와 더 가까운 수치를 보임을 알 수 있다. 즉, VAE를 통해 만들어진 molecule들이 realistic한 특성을 보인 것이다.
이번 글을 통해 우리는 molecular generative model의 가장 기본이 되는 chemical VAE이 어떻게 작동되는지에 대해 알아보았다. 앞으로 다양한 graph의 generative model들과 discriminative model들에 대해 다루어보겠다.
References
Gómez-Bombarelli, R., Wei, J. N., Duvenaud, D., Hernández-Lobato, J. M., Sánchez-Lengeling, B., Sheberla, D., ... & Aspuru-Guzik, A. (2018). Automatic chemical design using a data-driven continuous representation of molecules. ACS central science, 4(2), 268-276.








최근댓글