Process Tree란, 트리 구조를 이용한 프로세스 모델 language이다. 트리 구조를 가지기 때문에 각 노드(액티비티)가 어떤 관계를 가지고 있는지를 한 번에 파악할 수 있다는 장점을 가진다. 또한 프로세스 트리는, petri net, workflow net, BPMN model 등의 보통의 프로세스 모델들이 가지는 deadlock, livelock 등의 문제들 없이, 완전히 soundness를 보장한다는 아주 강력한 장점을 가진다. 그렇기 때문에 프로세스 트리는 inductive miner, ETM 등 다양한 process discovery 알고리즘에 활용되고는 한다. 이번 포스팅에서는 프로세스 트리가 무엇이고 어떻게 생겼는지, 페트리 넷으로부터 어떻게 만들어지는지, 그리고 프로세스 트리의 장단점에 대해서 알아보도록 하겠다.
Process Tree의 형태 및 구성 요소
Process Tree는 액티비티와 operator로 구성된 트리 구조를 가진다. 설명만 해서는 감이 잡히지 않기 때문에 눈으로 먼저 보도록 하겠다.
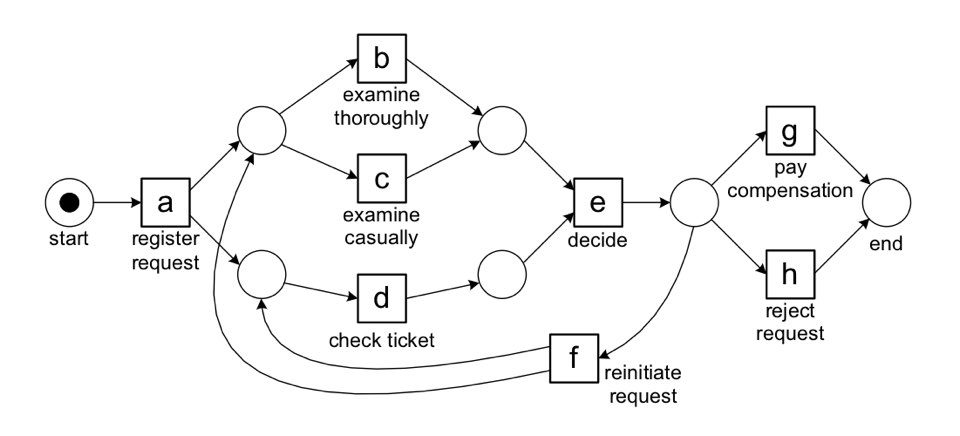
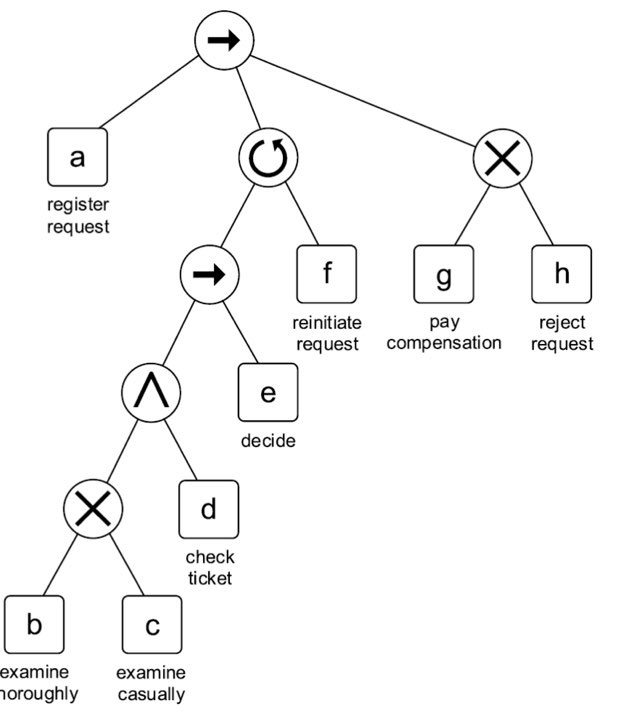
위 그림에서도 볼 수 있듯이, 프로세스 트리는 leaf(자식 노드가 없는 노드. 위 그림에서 네모로 표시)의 형태로 표현되는 액티비티들과, inner node(자식 노드가 있는 노드. 위 그림에서 원으로 표시)의 형태로 표현되는 operator로 이루어진다. 이러한 프로세스 트리는, 다음과 같이 텍스트의 형태로도 나타낼 수 있다.
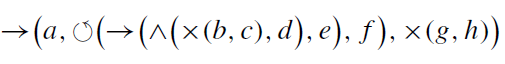
그렇다면 이제 프로세스 트리의 구성요소들에 대해서 더 자세하게 알아보도록 하겠다.
Activity
프로세스 트리의 액티비티에는 두 종류가 있다.
첫 번째는 normal activity이다. 이는 우리가 여태까지 봐왔던, 보통의 액티비티를 말한다.

두 번째는 silent activity이다. 이는 이름 그대로, 아무 액티비티도 일어나지 않는 액티비티를 말한다.

아무 액티비티도 일어나지 않는 액티비티라니.. 이 무슨 모순적인 말도 안 되는 소리야... 이것은 아래 operator의 parallel composition 부분에서 더 직관적으로 이해할 수 있으니 일단 넘어가도록 하자.
Operator
프로세스 트리의 operator에는 네 종류가 있다.
첫 번째는 sequential composition이다. sequential composition은 단순히 순서대로 액티비티들이 하나하나 진행되는 것을 말한다.

두 번째는 exclusive choice이다. exclusive choice는 여러 액티비티들 중 단 하나만 선택하여 실행하는 것을 말한다.

세 번째는 parallel composition이다. parallel composition은 모든 액티비티들이 병렬적으로 실행되는 것을 말한다. 즉, 모든 액티비티들이 실행되기는 하지만 순서 없이 실행된다. 위에서 말했던 silent activity가 바로 여기서 나타난다. place와 place가 연결되는 것을 방지하기 위해서 silent activity가 들어가는 것이다.

네 번째는 redo loop이다. redo loop는 액티비티들 중 하나가 실행되면, 다시 돌아가 그 액티비티 혹은 다른 액티비티들을 다시 실행하거나 다음으로 넘어갈 수도 있는 loop를 말한다. 아래 그림을 보면 이해가 더 쉬울 것이다.

Process Tree 만드는 법
그렇다면 이제 Process Tree를 어떻게 만드는지에 대해 알아볼 차례이다. 이번 포스팅에서는, 프로세스 트리에 좀 더 익숙해지기 위해 페트리 넷으로부터 프로세스 트리를 만들어내는 방법만을 알아보도록 하겠다. 이벤트 로그로부터 프로세스 트리를 만드는 알고리즘은 Inductive Miner 포스팅에서 설명하도록 하겠다. (사실 이것이 프로세스 트리 글을 쓰는 이유이다.) 다시 우리의 원래 페트리 넷으로 돌아가자.
페트리 넷으로부터 프로세스 트리를 쉽게 만들기 위해서는, 전체의 구조를 보는 것이 아니라 액티비티 하나하나의 구조에 집중해야 한다. 즉, 현재 집중하는 액티비티를 제외하고는 모두 other stuff로 취급하는 것이 중요하다. 이것이 무슨 말인지 천천히 단계별로 하나씩 알아보겠다.
맨 처음에 액티비티 a가 일어나고, 다른 액티비티들이 일어난다. 그러면 우리는 아래 그림과 같이 나머지 액티비티들은 other stuff로 취급한다.

이에 따라 process tree를 만들면 다음과 같은 형태가 될 것이다.

다음으로, a 액티비티 이후에는 b와 c 사이의 exclusive choice와 병렬적인 d 액티비티가 일어난다. 그리고 이 액티비티들은 마지막에 e로 follow된다.

이에 따라 process tree를 만들면 다음과 같은 형태가 된다.
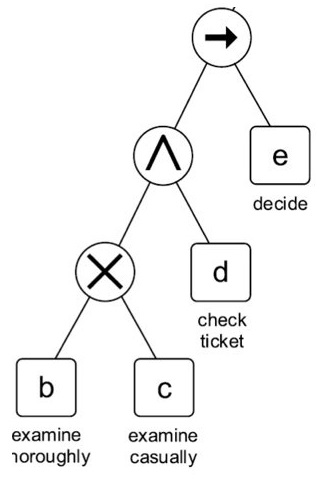
다음으로, 아래의 other stuff를 먼저 살펴보면, f로의 redo가 일어남을 알 수 있다.

이에 따라 process tree를 만들면 다음과 같은 형태가 된다.

마지막으로 남은 other stuff는 g와 h 사이의 exclusive choice이다.

이를 마지막으로 프로세스 트리에 붙이면 다음과 같이 프로세스 트리가 완성된다!

Process Tree의 장단점
장점
프로세스 트리의 가장 강력한 장점은 soundness를 보장한다는 것이다. 위에서도 말했듯이, 대부분의 프로세스 모델들은 deadlock, safeness 등의 문제점을 가지는 경우가 많은데, 프로세스 트리는 모델을 디자인할 때부터 soundness를 보장하기 때문에 위와 같은 문제점이 전혀 생기지 않는다.
단점
프로세스 트리의 단점은 프로세스 전체에 대한 global한 정보를 얻기 힘들다는 점이다. 하나의 translating operator를 보았을 때, 해당 leaf 액티비티에 대한 정보는 정확하게 알 수 있지만, 그 외의 부분에 대한 정보는 전혀 알 수 없는 것이다. 즉, local에 대한 정보는 얻기 쉽지만 global한 정보는 전혀 알 수 없다는 단점을 가진다.
References
1. Course: Advanced Process Mining. RWTH. Dr.ir. Sebastiaan J. van Zelst
2. Section 7.5 of the book “Process Mining: Data Science in Action” (Second Edition) by Wil M.P. van der Aalst.








최근댓글