여태까지 살펴 본 알파 알고리즘, 휴리스틱 마이닝 등의 process discovery 알고리즘들은 굉장히 직접적이고 확실한 프로세스 모델을 도출했다. 이번 포스팅에서는, 이와는 좀 다르게 randomization을 기반으로 하는 evloutionary approach로 프로세스 모델을 도출해 내는 Genetic Process Discovery에 대해 알아보려고 한다.
Genetic Process Discovery

다른 분야에서 사용되는 Genetic algorithm과 똑같이, genetic process discovery는 initialization, selection, reproduction, termination의 네 단계로 이루어져 있다.
Initialization
Initialization 단계에서는 첫 번째 세대(initial population)이 만들어진다. 이 세대는 개체(individual)들로 구성되는데, 여기서 각 개체는 프로세스 모델이다. 즉, 로그에 나타나는 모든 액티비티들을 이용하여 프로세스 모델이 랜덤하게 만들어지는 것이다. 모델이 랜덤하게 만들어지기 때문에 당연히 실제 로그의 움직임을 나타내는 모델과는 거리가 있지만, 우연히 로그의 일부와 맞는 프로세스 모델이 만들어지기도 할 것이다.
여기에서 우리는 각 individual을 어떻게 표현할지 (Representation of individuals)를 정해야 한다. 프로세스 모델의 종류는 petri net, C-net, BPMN, EPC 등 굉장히 다양하다. 그렇기 때문에 우리는 각 individual을 어떤 프로세스 모델로 표현할 것인지, 그리고 이 프로세스 모델을 어떻게 표현할 것인지 등의 방법을 명확히 정의해야 한다.
Selection
Selection 단계에서는 각 individual, 즉 각 프로세스 모델이 로그에 얼마나 잘 부합하는지(fitness - 4가지 criteria 중의 fitness가 아닌 모델의 성능을 의미하는 단어로 쓰였다)를 계산한다. 이를 고려할 때에는 fitness, generalization, simplicity, precision의 네 가지 criteria를 모두 고려한다. 네 가지 criteria를 모른다면 다음 포스팅을 참고하도록 한다. 여기에서 우리는 4가지의 criteria를 어떻게 balancing하여 모델을 평가할 것인지, 즉 fitness function으로 무엇을 사용할지를 명확히 정의해야 한다. 물론, 모델을 도출하는 사람의 선호에 따라 특정 criteria에 가중을 두는 것 등도 가능하다.
2019/07/29 - [Theory] - Process Model의 Quality 평가 (어떤 프로세스 모델이 좋은 모델일까?)
Process Model의 Quality 평가 (어떤 프로세스 모델이 좋은 모델일까?)
우리는 알파 알고리즘, inductive miner, heuristic miner 등 다양한 process discovery 알고리즘들을 통해 프로세스 모델을 도출할 수 있다. 그렇다면 이 다양한 process discovery 알고리즘 중 가장 좋은 알고리..
process-mining.tistory.com
이 단계에서 가장 좋은 fitness를 가지는 1%는 elitism으로 분류되어 별다른 수정 없이 다음 세대로 이동된다. 이 단계를 통해 좋은 모델들이 다음 세대로 전해지지 않는 것을 방지한다.
그리고 남은 99%에 대해 tournament를 통해 새로운 세대를 만들어내기 위한 parent들이 선별된다. 이는 다양한 방법들이 활용될 수 있는데, 그 예시로는 랜덤하게 뽑은 5개의 모델 중 가장 좋은 성능의 1개의 모델들을 parent로 넣는 방법이 있다.
Reproduction
Reproduction 단계에서는 selection 단계에서 선별된 parent들을 이용해 새로운 프로세스 모델(offspring)을 만들어낸다. 이 단계에서는 crossover과 mutation이 진행된다.
Crossover은 두 개의 parent를 이용해 child model을 만들어내는 것을 의미한다. Crossover의 예시를 하나 들자면, 아래 방법과 같이 진행될 수 있다. 같은 액티비티 종류를 가지는 두 개의 parent를 선택하여 정해진 액티비티(e,f)에 대해 그 부분에서 모델을 잘라 두 부분을 교환하는 것이다.
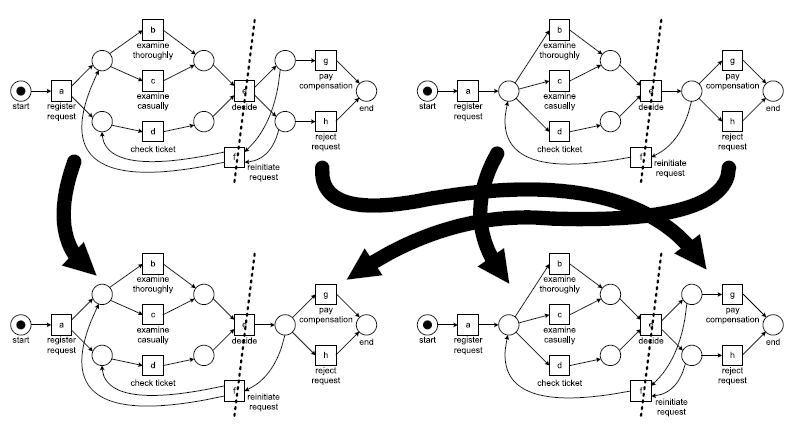
mutation은 이 child model에 대해 place를 추가하거나 arc를 추가하는 등의 방법으로 모델을 수정하는 것을 말한다.

이 mutation과 crossover 단계가 끝나면 결과 프로세스 모델이 WF-net이 아닌 경우 등이 있을 수 있기 때문에 원래 의도한 프로세스 모델으로 이를 맞춰주는 repair action이 필요하다.
Termination
Termination 단계는 말 그대로 알고리즘의 종료이다. 일정 기준 (fitness 등)을 만족하는 프로세스 모델이 도출되면 알고리즘이 종료된다.
이번 포스팅에서는 Genetic Process Discovery에 대해 알아보았다. 물론, Genetic Process Discovery는 모든 모델에 대해 fitness를 하나하나 계속 계산해야 하기 때문에 큰 모델이나 로그에 대해서는 계산 시간이 너무 오래 걸린다는 단점을 가지기도 하지만, 휴리스틱한 방법을 genentic process discovery에 결합하여 process discovery를 한다면 더 좋은 결과를 가질 수 있다.
References
1. Section 7.3. of Wil van der Aalst. Process Mining: Data Science in Action (Second Edition) : Springer, 2016.








최근댓글