간만에 프로세스 마이닝. 조회수 상위 10개 중에 프로세스 마이닝이 2개밖에 없어도 난 괜찮아~
프로세스 마이닝은 실제 프로세스가 어떻게 흘러갔고, 표준 프로세스로부터 벗어난 프로세스가 무엇이고, 병목은 어디에서 일어나는지 등을 분석할 수 있게 해준다. 하지만 프로세스 마이닝은 이벤트 로그로부터 분석을 실행하기 때문에 과거에 집중(backward-looking)한다. 이에 반해 시뮬레이션은 미래에 집중한다. 시뮬레이션을 통해 우리는 특정 상황과 환경을 가정하고 해당 환경에서 이벤트 로그가 어떻게 발생할 것인지를 도출할 수 있다. 그러므로 프로세스 마이닝과 시뮬레이션은 상호보완적이다. 이번 포스팅에서는 이렇게 프로세스 마이닝과 시뮬레이션이 어떻게 서로 상호보완적으로 연결될 수 있는지를 보여주는 예시 중 하나인 automated BPS에 대해 알아보겠다.
Business Process Simulation (BPS)
Business Process Simulation(BPS)은 프로세스 모델에 작업시간, 대기시간, 빈도 등 다양한 정보를 담아 이를 기반으로 하여 시뮬레이션을 통해 trace들을 도출하는 것을 말한다. 우리는 이러한 BPS를 통해 도출된 trace들의 퍼포먼스(case duration, waiting time 등)를 비교 분석함으로써 어떤 방향으로 프로세스 모델을 바꾸어야 할지를 결정할 수 있고, 이렇게 어떤 방향으로 프로세스 모델을 향상시킬지를 결정하는 것이 BPS의 최종 목적이라고 할 수 있다.
그렇다면 좋은 BPS는 무엇일까? 당연히 현실을 정확하게 반영하는 시뮬레이션 모델일 것이다. 즉, BPS의 결과로 도출된 이벤트 로그와 실제 이벤트 로그가 유사하다면 좋은 BPS 모델이 만들어졌다고 할 수 있을 것이다.
전통적인 BPS는 시뮬레이션 모델을 만들 때에 manual하게 작업을 진행했다. 즉, 전문가들이나 현업 종사자들을 인터뷰함으로써 그들의 생각에 맞는 프로세스 모델을 도출하고, 이를 기반으로 시뮬레이션을 한 것이다. 하지만 이러한 과정은 시간이 오래 걸리고, 현실을 반영한 정확한 모델을 도출할 수 없다는 단점을 가진다.
이러한 단점을 극복하기 위해서 등장한 개념이 BPS based on Process Mining이다. 즉, 프로세스 마이닝의 Process discovery를 프로세스 모델 도출 과정에서 사용하고, 이 모델에 이벤트 로그로부터 도출한 지표(작업시간, 대기시간 등) 정보를 붙여 시뮬레이션에 활용하는 것이다. 하지만 이러한 방법은 이벤트 로그로부터 도출한 지표를 직접적으로 활용하기 때문에 BPS 모델의 정확도를 자동으로 튜닝할 수 없다.
이러한 단점을 극복하기 위해서 등장한 개념이 Automated BPS이다. Automated BPS는 BPS based on PM과 같이 Process discovery를 프로세스 모델 도출 과정에서 사용하지만, 이 모델에 사용하는 simulation parameter를 따로 도출한다. 이 simulation parameter들을 바꿔가면서 최적의 BPS 모델을 자동으로 최적화하여 찾아내는 것이다.

Overview
* Automated BPS를 도출할 때는, 이벤트 로그에 case id, activity, resource, start timestamp, end timestamp가 모두 있다고 가정한다.
이 Automated BPS 모델은 다음과 같은 구조로 이루어진다.

각 단계를 간단하게 살펴보면 다음과 같다.
- Pre-processing: 이벤트 로그로부터 프로세스 모델(BPMN)을 도출하고 이벤트 로그를 모델에 fitting하게 가공하는 과정.
- Processing: simulation parameter를 도출하고, 프로세스 모델에 simulation parameter를 결합하여 BPS 모델을 도출하는 과정.
- Simulation: 위 단계에서 만들어진 BPS 모델을 기반으로 시뮬레이션하여 trace를 도출하는 과정.
- Assessment and optimization: 도출된 이벤트 로그와 기존의 이벤트 로그를 비교하여 정확도를 평가하고, 시뮬레이션 파라미터를 튜닝하여 최적의 BPS 모델을 도출하는 과정.
이제 각 단계에 대해 하나하나 살펴보겠다.
Pre-processing
Pre-processing 단계는 위에서도 말했듯이 이벤트 로그로부터 프로세스 모델(BPMN)을 도출하고 이벤트 로그를 모델에 fitting하게 가공하는 과정이다. 이는 또 다시 이벤트 로그로부터 프로세스 모델을 도출하는 Control Flow Discovery , 이벤트 로그를 모델에 fitting하게 가공하는 Trace Alignment의 두 개의 과정으로 나누어진다.
Control Flow Discovery
Control Flow Discovery 과정에서는 이벤트 로그로부터 BPMN 프로세스 모델을 도출한다. 이 때, BPMN 모델을 도출하는 process discovery 알고리즘은 split miner를 사용한다. (Split miner에 대한 포스팅은 미래의 나..! 화이팅..!)
Trace Alignment
Trace Alignment 과정에서는 도출된 프로세스 모델에 이벤트 로그의 fitness가 1이 되도록 이벤트 로그를 가공하는 과정한다. 이 과정이 있는 이유는 뒤의 processing 과정에서 이벤트 로그를 프로세스 모델에 replay함으로써 여러 파라미터를 도출해야 하기 때문이다. (fitness가 1이어야 모든 이벤트 로그가 100% replay가 가능하다.) 이를 위해 우선 이벤트 로그의 fitness를 Alignment based conformance checking으로 계산한다. 그리고 fitness가 1이 아니라면, 아래 3가지 옵션 중 하나를 선택하여 이벤트 로그의 fitness를 1로 만드는 log repair를 진행한다.
- Removal: 프로세스 모델에 fitting하지 않는 모든 trace를 삭제한다.
- Replacement: 프로세스 모델에 fitting하지 않는 trace를 가장 비슷한 fitting trace로 대체한다.
- Alignment: log-move는 삭제하고, model-move는 trace에 activity를 추가한다.

Processing + Simulation
Processing 단계는 simulation parameter를 도출하고, 프로세스 모델에 simulation parameter를 결합하여 BPS 모델을 도출하는 과정이다. 이는 또 다시 simulation parameter를 도출하는 parameters extraction 단계와 프로세스 모델에 simulation parameter를 결합하는 simulation model assembly 단계로 나누어진다.
Parameters extraction
시뮬레이션으로부터 도출할 수 있는 parameter는 크게 5가지로 분류할 수 있고, 그것은 다음과 같다.
- Replay the event log: 이벤트 로그를 프로세스 모델 위에 replay함으로써 processing time, enablement time, 빈도, 대기 시간 등을 도출한다.
- Discover the inter-arrival distribution: case 시작 이후 바로 다음 case가 시작할 때까지 걸리는 시간을 말한다. 이 때 이 시간은 평균 등으로 구하는 것이 아닌 pdf(확률 밀도 함수)를 구한다. Normal, Exponential, Uniform, Gamma distribution 등 다양한 분포 중 적절한 분포를 선택한다. (각 분포에 대한 설명은 먼 미래의 나 화이팅..!)
- Conditional branching probabilities: XOR/OR split gate에서의 다음 task 확률 분포를 말한다.

- Activity processing times: 각 activity의 작업 시간을 말한다. inter-arrival time과 마찬가지로 pdf를 구한다.
- Resource pools: 각 activity를 수행하는 resource 군집을 말한다. 비슷한 activity를 수행하는 resource를 군집화한 후 각 activity를 해당 resource pool에 할당하는 식으로 구한다. (resource 군집화는 미래의 나 화이팅)
Simulation model assembly + Simulation
위 과정에서 simulation parameter를 모두 도출했으면 각 파라미터들을 앞서 구했던 프로세스 모델(BPMN)에 결합함으로써 BPS 모델을 완성한다. 완성된 BPS 모델로부터 trace를 도출하여 이벤트 로그를 만듦으로써 시뮬레이션 과정 또한 완료된다.
Assessment and optimization
Assessment and optimization 과정은 도출된 이벤트 로그와 기존의 이벤트 로그를 비교하여 정확도를 평가하고, 시뮬레이션 파라미터를 튜닝하여 최적의 BPS 모델을 도출하는 과정이다. 이 과정 또한 BPS 모델의 정확도를 평가하는 Assess BPS model accuracy 과정과 파라미터를 튜닝하는 Hyper-parameter optimization 과정으로 이루어진다.
Assess BPS model accuracy
위에서 좋은 BPS 모델은 현실을 정확하게 반영하는 모델이고, 이는 BPS의 결과로 도출된 이벤트 로그와 실제 이벤트 로그가 유사한 것이라고 했다. 그렇다면 이 '유사하다'는 것을 어떻게 정의할 수 있을까? 이는 Event Log Similarity(ELS)로 표현할 수 있다. ELS는 Mean Absolute Error(MAE)와 Business Process Trace Distance(BPTD)의 두 가지 방법으로 계산할 수 있다.
- Mean Absolute Error(MAE): 두 이벤트 로그의 cycle time을 비교하여 이들의 MAE가 작으면 유사도가 높다고 판단한다. Cycle time만 고려하기 때문에 trace 내 액티비티의 순서 등을 고려하지 않는다는 단점을 가진다.
- Business Process Trace Distance(BPTD): trace 간 액티비티 차이와 cycle time 차이를 모두 고려한다. 이는 아래와 같은 식으로 계산할 수 있다.

위 식은 Damerau-Levenshtein distance를 cycle time을 반영할 수 있는 형태로 변형시킨 식이다. (Damerau-Levenshtein distance도 ㅁ ㅣㄹ ㅐㅇㅢ ㄴ ㅏ..! 이 모든 걸 설명하다 보면 포스팅이 너무 길어진다.. 지금은 자세한 설명은 위키피디아를 참고하세요 ㅠㅠ)
이렇게 BPTD를 이용해 trace 간의 유사도를 계산하면, 이벤트 로그 전체의 ELS는 다음과 같은 식으로 계산할 수 있다.
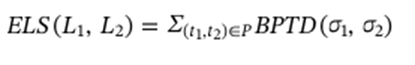
즉, 모든 trace 쌍에 대해 일대일대응으로 BPTD의 합을 구하면 두 이벤트 로그의 유사도인 ELS 값을 구할 수 있는 것이다. 이 때, 이 trace의 일대일대응 pair는 Hungarian algorithm(미래의 나. 어유 미래 유니는 좋겠다~ 소재도 많고~)을 활용하여 minimal distance pairing을 가지는 trace의 쌍을 찾는다.
Hyper-parameter optimization
마지막으로, Hyper-parameter를 optimization한다. 우리가 이렇게 긴 과정 동안 BPS 모델을 만들 때에 사용한 하이퍼파라미터는 다음과 같다.

이 파라미터들을 manual하게 하나하나 반복하면서 튜닝하지는 않고, Tree-structured Parzen Estimator(TPE)(ㅁㄹㅇㄴ ㅋㅋ)를 사용하여 ELS를 최대로 하는 BPS 모델을 찾아낸다. 이렇게 최적의 BPS 모델을 찾을 수 있는 것이다.
이번 포스팅에서는 긴긴 과정 끝에 Automated BPS를 만드는 방법에 대해 알아보았다. 프로세스 마이닝과 시뮬레이션은 상호보완적으로 활용될 수 있는 부분이 굉장히 많기 때문에 좋은 연구 분야 같다는 생각이 든다. 사실 독일에 맨 처음 컨택할 때 시뮬레이션+프로세스 마이닝으로 컨택했었는데 전혀 다른 것 하고 돌아왔는데 다시 이걸 하는 중이라니 사람 일이란.. 요즘 왜 이렇게 평일 밤에 블로그 쓰면 눈이 피로하지.. 루테인 사야하나.. 물론 요즘 평일 밤이라고 하기엔 평일 밤에 쓴 빈도가 너무 낮아서 약간 양심없네.. 의식의 흐름.. 안녕..
References
1. Manuel Camargo, Marlon Dumas, OsOscar González-Rojas, Automated discovery of business process simulation models from event logs, Decision Support Systems, Volume 134, 2020.








최근댓글