Conformane Checking (적합도 검증)이란, 프로세스 모델이 실제 이벤트 로그에 얼마나 잘 부합하는지, 즉 프로세스 모델이 실제 데이터와 비교해봤을 때 얼마나 잘 맞는지를 검증하는 것을 말한다. 이에는 다양한 방법들이 존재하는데, 오늘은 그 중에서도 가장 기본이 되고 가장 쉬운 Footprint Comparison Conformance Checking에 대해 알아 보려고 한다.
Footprint Matrix란?
* 이 부분은, 지난 Alpha Algorithm이란? 포스팅에서 설명한 부분이기 때문에 이를 이해했다면 넘어가도 좋다.
2019/05/31 - [Theory/Process Discovery] - 알파 알고리즘 (Alpha Algorithm)이란?
알파 알고리즘 (Alpha Algorithm)이란?
알파 알고리즘(Alpha Algorithm)은 이벤트 로그로부터 프로세스 모델을 찾는, Process Discovery의 가장 기본이 되는 가장 단순한 알고리즘이다. 여태까지 Process Discovery가 무엇인지를 직관적으로 이해하지 못..
process-mining.tistory.com
Footprint Matrix를 만들 때에는 이벤트 로그의 요소 중 액티비티의 순서에만 집중한다. 하나의 케이스 안에서 액티비티가 어떤 순서대로 일어났는지에 대한 정보만 필요로 하는 것이다. 그 정보만 나타낸 이벤트 로그의 형태가 바로 아래 형태이다.

가장 먼저 해야할 일은 이 이벤트 로그의 액티비티 간의 log-based ordering relations를 파악하는 것이다.

어려운 단어와 수식들이 나오기 시작하지만 하나씩 설명할테니 당황할 필요 없다. 액티비티 간의 relation에는 총 4가지 종류가 있다.
첫 번째 relation은 Direct Succession (>)이다. 이는 이벤트 로그 내의 하나의 trace 내에서 바로 뒤에 따라오는 (directly followed) 관계의 액티비티를 의미한다. 예를 들어, 위 로그에서는 (a,b), (b,c), (c,d), (a,c), (c,b), (b,d), (a,e), (e,d)가 이에 해당한다.
두 번째 relation은 Casuality(->)이다. 이는 a가 b에 대해서 >이지만, 그 역은 성립하지 않는 경우를 말한다. 예를 들어, 위 로그에서 (b,c)와 (c,b)가 모두 존재하기 때문에 b와 c는 ->의 관계가 아니다. 하지만 (a,b), (c,d), (a,c), (b,d), (a,e), (e,d)는 모두 ->의 관계인 것이다.
세 번째 relation은 Parallel(||)이다. 이는 >에서 ->를 뺀 모두이다. 즉, >의 역이 성립하는 (b,c)와 (c,b)의 관계를 말한다.
네 번째 relation은 Choice(#)이다. 이는 아무 관계가 없다는 것이다. 즉, 위에서 나온 모든 relation의 쌍을 제외한 모든 쌍이 #의 관계이다.
우리의 로그에서 이를 정리하면 다음과 같다.

그렇다면, 이를 이용하여 Footprint Matrix를 만들어야 한다. 이는 정말 간단하다. 그저 모든 액티비티 relation에 대해서 위의 해당하는 relation을 채워 넣으면 된다. 그 결과는 다음과 같다.

Conformance Checking
위 설명대로 이벤트 로그로부터 Footprint Matrix를 도출할 수 있다. 같은 방법으로 프로세스 모델으로부터 Footprint Matrix도 도출이 가능할 것이다. 예시 프로세스 모델과 함께 설명해보겠다.
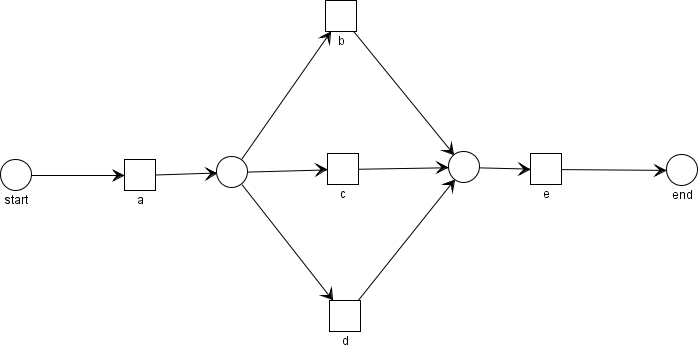
위 그림과 같은 petri net이 있다. 여기에서 도출될 수 있는 모든 이벤트 로그는
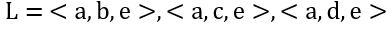
위와 같고, 이를 이용하여 relation을 도출하면 다음과 같다.

그리고 마지막으로, 이를 이용하여 footprint matrix를 만들면 다음과 같다.

이제 프로세스 모델로부터 도출된 Footprint Matrix와 실제 이벤트 로그로부터 도출된 Footprint Matrix를 비교할 차례다.

이들을 보면, 빨간 네모가 있는 부분에 대해서 relation이 다름을 알 수 있고, 이들을 이용하여 Footprint Conformance를 계산하는 식은 다음과 같다.

그러므로 우리의 예시에서 Footprint Conformance의 값은

이 된다.
한계점
Footprint Matrix Conformance Checking에는 몇 가지의 명확한 한계점이 존재한다.
1. 이벤트 로그의 빈도에 대한 정보를 전혀 고려하지 않는다.
오로지 액티비티 간의 relation에만 초점을 맞추기 때문에, 실제 이벤트 로그에서 100번 일어난 relation이 틀리든 1번 일어난 relation이 틀리든 conformance 값 자체에는 똑같은 영향을 미치는 것이다.
2. Fitness, Precision, Generalization을 각각 고려하지 못한다.
Footprint Conformance라는 단 하나의 값만을 도출해내기 때문에, fitness, precision, generalization에 대한 각각의 값을 얻지 못하고 오로지 하나의 값에만 의존한다.
3. 프로세스 패턴을 파악하기가 힘들다.
Directly Follows relation에만 의존하기 때문에, 각 액티비티 두 개씩에 대한 정보만을 이용한다. 그렇기 때문에 하나의 케이스 내에서 어떤 패턴이 일어났는지에 대한 정보는 전혀 얻을 수가 없다.
이렇게 Footprint Matrix Conformance Checking은 적합도 검증 방법들 중에 가장 간단하고 쉬운 방법이지만, 동시에 명확한 한계점이 존재하는 방법이기도 하다. 그렇기 때문에 최근의 적합도 검증 방법으로는 거의 사용되지 않지만, 가장 기본적이고 직관적인 방법이기 때문에 알아놓으면 도움이 될 것이다.
References
1. Business Process Intelligence. Prof. Wil M.P. van der Aalst. RWTH
2. Advanced Process Mining. Dr. Sebastiaan J. van Zelst. RWTH








최근댓글