GAN은 generative adversarial network의 줄임말로, VAE, diffusion model과 같은 generative model의 한 종류로써 데이터를 생성하는 generator와 데이터를 구별하는 discriminator가 경쟁하는 과정을 통해서 데이터를 학습한다. 이번 글에서는 GAN이 무엇인지와 함께, 어떤 원리로 동작하는지에 대해 수식과 함께 살펴보겠다.
Motivation
GAN은 앞서 언급했듯이, 데이터를 생성하는 generator와 데이터를 구별하는 discriminator로 이루어져 있다. Generator는 최대한 실제처럼 보이는 데이터를 생성함으로써 discriminator를 속이려고 시도하고, 이에 반해 discriminator는 실제 데이터와 만들어진 가짜 데이터를 구별하려고 노력한다. 이를 그림으로 표현하면 아래와 같다.

이렇게 서로 경쟁하면서 학습을 함으로써, generator는 점점 더 실제와 같은 데이터를 생성하게 되고, discriminator는 점점 더 실제와 가짜 데이터를 잘 구별할 수 있게 될 것이다. 결론적으로, generator가 실제 데이터와 굉장히 비슷한 데이터를 생성하는 generative model로서의 역할을 할 수 있게 되는 것이다.
구조
GAN의 간략한 구조를 이해했다면, 이제 GAN의 구조를 수식을 통해서 알아보도록 하겠다. 우선 우리의 generator를 $G$, 그것의 parameter를 $\theta$, discriminator를 $D$, 그것의 parameter를 $\phi$라고 하자. 또한 1을 실제 데이터, 0을 가짜 데이터를 나타내는 label이라고 하자. 그러면 우리는 GAN이 학습되는 과정에서의 objective function을 아래 식과 같이 표현할 수 있다.
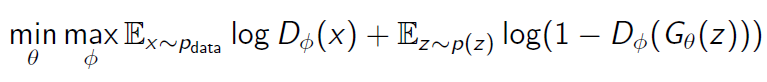
Discriminator는 위 식에서, $D(x)$를 최대한 1에 가깝게 만들고, $D(G(z))$를 최대한 0에 가깝게 만듦으로써 objective function을 최대화하는 것을 목적으로 한다. 여기서 $x$는 실제 데이터이고, $z$는 가짜 데이터를 만드는 분포이다. 그러므로 $D(x)$를 최대한 1에 가깝게 만듦으로써 실제 데이터를 1로 분류하고, $D(G(z))$를 최대한 0에 가깝게 만듦으로써 가짜 데이터를 0으로 분류하도록 discriminator를 학습하는 것이다.
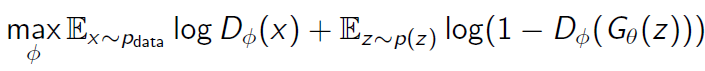
Generator는 위 식에서, $D(G(z))$를 최대한 1에 가깝게 만듦으로써, objective function을 최소화하는 것을 목적으로 한다. $D(G(z))$를 최대한 1에 가깝게 만드는 것을 다시 말하면, discriminator가 가짜 데이터를 1로 분류하도록 속일 수 있는, 최대한 실제 데이터와 가까운 가짜 데이터를 만드는 방향으로 generator를 학습하는 것이다.

하지만 위 objective function을 활용해서 GAN을 학습하면 실제로는 학습이 잘 되지 않는 경우가 있다. 그 이유는, generator의 성능이 안 좋을 때, 해당 objective function을 따르면 gradient가 굉장히 작아서 학습이 빠르게 될 수 없기 때문이다. 다음 그래프를 보자.

위 그래프를 보면, $log (1-D)$는 $D(G(z))$가 0에 가까울 때, gradient가 0에 가깝기 때문에 학습이 잘 되지 않을 수 있다. 그렇기 때문에 우리는, 위의 generator objective function 대신에 다음 objective function을 학습에 활용한다.

이 objective function은 기존의 generator의 objective function과 같은 의미를 가지고 있으면서도, 위 그래프에서 볼 수 있듯이 generator가 잘 학습이 되지 않았을 때의 gradient가 크기 때문에 학습이 비교적 잘 된다.
한계
GAN은 대표적인 generative model로, image generation 등에서 아주 좋은 성능을 보였다. 하지만 이러한 GAN도 한계점을 가지고 있다. GAN의 대표적인 한계점은 mode-collapse이다. Mode-collapse는 generator와 discriminator 중 하나가 너무 학습이 잘 돼서 다른 하나의 학습이 진행되지 않는 것을 말한다. 예를 들어, generator가 하나의 정말 진짜같은 가짜 데이터를 생성한다면, discriminator는 이를 항상 구별할 수 없을 것이고, discriminator는 더 이상 학습을 진행할 수 없을 것이다.

이번 글에서는 GAN이 무엇인지에 대해 수식을 통해 살펴보았고, GAN의 한계점이 무엇인지에 대해서도 간단하게 알아보았다.
References
1. Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. Advances in neural information processing systems, 27.
2. Berthelot, D., Schumm, T., & Metz, L. (2017). Began: Boundary equilibrium generative adversarial networks. arXiv preprint arXiv:1703.10717.








최근댓글