Byte pair encoding (BPE)는 문장 혹은 단어 안에 있는 글자들을 적절한 단위로 나누는 subword tokenizer의 하나로, token들의 빈도를 기반으로 높은 빈도의 토큰들을 merge해가며 최종 token들을 만들어내는 방법이다. 이번 글에서는 BPE가 어떻게 토큰들을 만들어내는지에 대해서 알아보겠다.
BPE tokenizer 알고리즘
BPE 알고리즘을 간단하게 표현하면 다음과 같다.
BPE 알고리즘은 기본적으로 문장이 pre-tokenize 되어 있다고 가정한다. 즉, 하나의 문장이 모두 이어져 있는 것이 아닌 띄어쓰기 등으로 분리되어 있다고 가정하는 것이다. 우리의 예시 문장이 "hug pug pun bun hugs"라고 하자. (아무런 뜻이 없는 그냥 예시 문장이다.) 그러면 이들 문장이 띄어쓰기 기준으로 pre-tokenize된다고 할 때, 우리는 "hug", "pug", "pun", "bun", "hugs"의 다섯 개의 단어들을 가지고 있는 것이다.
이제부터 BPE 알고리즘을 예시와 함께 살펴보겠다. 우리의 예시 문장 집합은 다음과 같다.
("hugs bun", 4)
("hugs pug", 1)
("hug pug pun", 4)
("hug pun", 6)
("pun", 2)위 예시에서 따옴표 안에 들어가 있는 것은 문장이고, 그 오른쪽에 있는 숫자는 각 문장의 빈도이다.
1. 우선, 각 pre-tokenize로 나누어진 단어들의 빈도를 계산한다. 이를 우리의 예시 데이터에 대해 계산하면 다음과 같다.
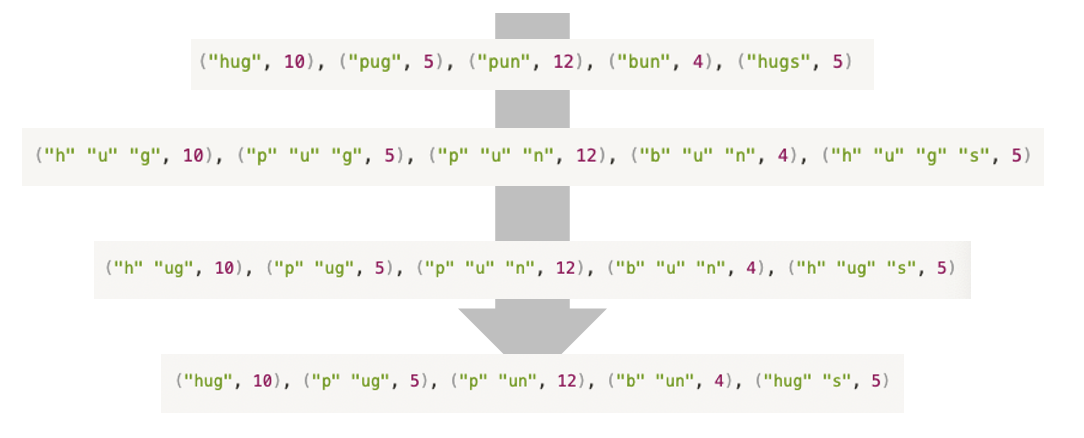
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)2. 다음으로, 각 단어들을 하나의 글자 (character) 단위로 나눈다.
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)3. 각 연속한 글자 pair들을 높은 빈도 순으로 merge한다. 우리의 예시에서는, 다음과 같은 pair들이 만들어질 수 있다.
("hu", "ug", "pu", "un", "bu", "gs")이들 각각의 pair에 대해서 빈도를 계산해보면, ug의 빈도가 20으로 이들 중 가장 높다. 그러므로 이들 pair를 merge한다.
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)다음으로, merge된 pair들을 포함해서 방금 한 과정을 반복한다. 한 step만 더 해보면, 다음과 같은 pair들이 만들어질 수 있다.
("hug", "pug", "pu", "un", "bu", "un", "hug", "ugs")이들 각각의 pair에 대해서 빈도를 계산해보면, un의 빈도가 16으로 가장 높다. 그러므로 이들 pair를 merge하면 다음과 같은 결과가 나온다.
("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)4. 이러한 과정을 우리가 원하는 merge 횟수 혹은 vocabulary size가 될 때까지 반복한다. 이 때, vocabulary size는 각각의 merge된 유니크한 토큰과 merge되지 않은 유니크한 character의 합이다. 예를 들어, 우리가 원하는 vocabulary size가 6이라고 하자. 그러면 우리는 위 단계의 결과를 최종 vocabulary로 확정할 것이다. 도출된 최종 vocabulary는 다음과 같다.
("h" "ug" "p" "un" "b" "s")5. Training data를 기반으로 학습된 tokenizer를 활용해 새로운 데이터에 대해서도 tokenizing을 적용한다. 예를 들어, 다음과 같은 문장이 주어지면, 우리는 다음과 같이 tokenizing을 할 것이다.
("hunb bun hsp") -> ("h", "un" "b"), ("b", "un"), ("h", "s", "p")BPE 장단점
BPE는 간단한 구조를 가지고 있고, 빠른 속도로 작동한다는 장점을 가지고 있다. 하지만 pre-tokenizing을 가정하고 있기 때문에 띄어쓰기가 없는 중국어, 일본어 등의 언어에 대해서는 적용이 힘들다는 단점을 가진다.
이번 글에서는 byte-pair encoding이 무엇인지에 대해 알아보았다. 갑작스러운 NLP 게시글인데 조금 블로그가 잡학이 되어가고 있는 것 같지만 한 번 분위기 전환을 위해 써 보았다. 다음 글에서는 다른 tokenizer들에 대해서도 알아보겠다.
References
Hugging face https://huggingface.co/course/chapter6/5?fw=pt








최근댓글