GraphSAGE는 graph sample and aggregate의 줄임말로, 기존의 GCN 등의 GNN들이 해결하지 못했던 문제인 inductive setting에서의 node classification 문제를 해결할 수 있게 한 GNN 구조이다. 이번 글에서는 GraphSAGE가 무엇인지에 대해서 알아보겠다.
Motivation
GraphSAGE의 motivation을 이해하기 위해서는 transductive setting과 inductive setting이 무엇인지부터 알아야 한다.
Transductive setting
Transductive setting은 주어진 데이터셋에 대해서만 prediction을 진행하는 것을 말한다. 이러한 setting에서는 현재까지는 관측되지 않은 (unseen) 데이터에 대해서 일반화된 모델을 학습할 수 없다. 그렇기 때문에 이러한 setting은 우리가 모르는 분자 구조의 특성을 예측하는 등의 현실 문제를 푸는 데에는 사용하기 힘들다는 한계점을 가진다. 하지만 모든 상황에 적용될 수 있는 general function을 학습할 필요는 없기 때문에, 우리가 푸는 문제가 정해져있을 때는 좀 더 정확한 예측이 가능할 수도 있다.
이를 그래프에서의 node classification 문제로 가져 오면, 어떤 고정된 그래프 구조가 있고 이 그래프의 일부 노드들은 label이 있고, 일부는 없을 때 이 없는 노드들의 label을 예측하는 문제가 될 것이다. 그렇기 때문에 transductive setting에서는 그래프의 structure를 미리 알고 있다고 가정하고, 다른 구조를 가지는 그래프에 대해서는 노드 label 예측이 불가능하다.
Inductive setting
이에 반해, inductive setting은 unseen 데이터에 대해서도 일반적으로 적용될 수 있는 모델을 학습하는 것을 말한다. 즉, training 데이터에 대해서만 잘 작동하는 것이 아닌, test 데이터에 대해서도 잘 작동할 수 있는 모델을 학습하는 것이다. 이러한 setting이 요즘의 머신러닝 문제들에서는 가장 기본적인 setting이라고 할 수 있다.
이를 그래프에서의 node classification 문제로 가져 오면, 그래프에 포함된 모든 노드를 알지 못하고 새로운 형태의 그래프가 들어와도 이들에 대한 노드 label을 예측하는 것이 가능하다. 이는 주로 노드들의 feature나 local neighborhood 등을 고려하여 진행된다.
기존의 GCN 등 모델은 그래프의 구조가 고정되어 있다고 가정하고, transductive setting에서의 node classification 문제를 해결했지만, GraphSAGE는 inductive setting에서의 node classification도 가능하게 한다.
Method
구조
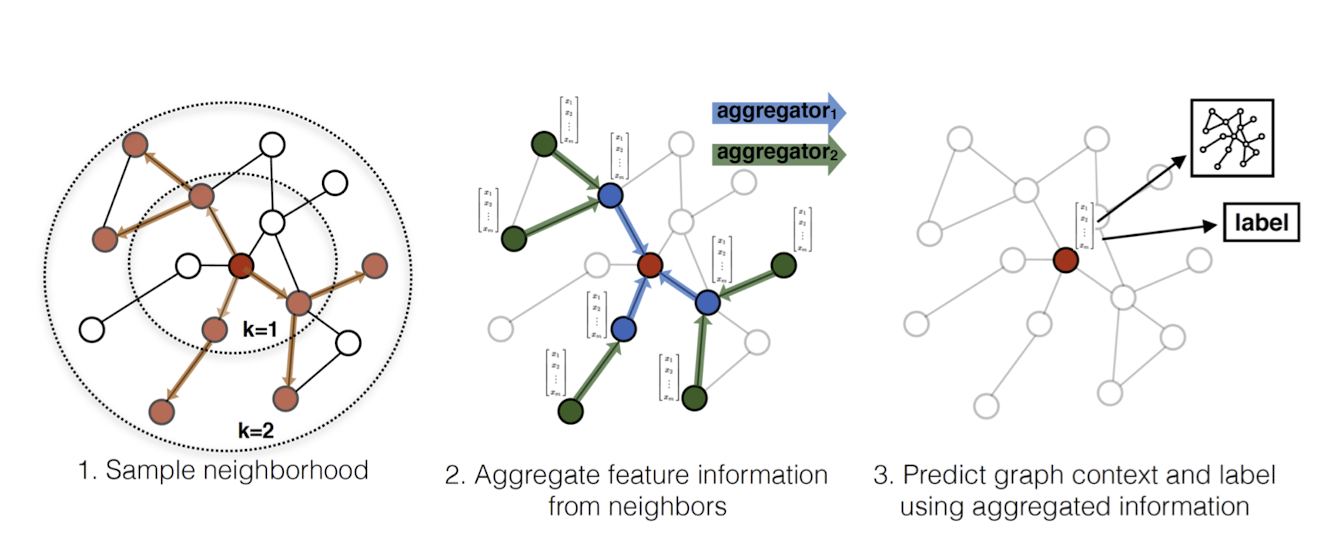
GraphSAGE는 위 그림과 같이 1) sample, 2) aggregate의 과정을 거쳐 학습을 진행한다. 이들 과정을 알고리즘 형태로 표현하면 다음과 같다.

위 알고리즘을 간단하게 설명하면, 우리가 K개의 aggregate 모델을 학습했다고 가정했을 때 각 aggregator k를 활용하여 노드 v의 이웃 샘플들의 k-1번째 hidden embedding을 aggregate하고, 이것과 노드 v의 k-1번째 hidden embedding을 활용하여 노드 v의 embdding을 update한다. 이제부터 sample과 aggregate 과정을 좀 더 구체적으로 설명하겠다.
Sample
Sample은 위에서 설명한 것처럼 aggregate할 때의 이웃 노드들을 일부만 샘플링하는 것을 말한다. GraphSAGE는 GCN과는 다르게 모든 이웃 노드들의 정보를 모두 활용하는 것이 아닌, 이웃 노드들 중 정해진 숫자만큼의 노드들을 샘플링한다. 이렇게 샘플링을 진행함으로써 우리는 노드의 embedding을 계산할 때의 time complexity를 적절하게 제한할 수 있다.
Aggregate
다음으로, aggregate는 이웃 노드들의 정보와 현재 노드의 정보를 조합하여 현재 노드의 다음 embedding을 결정하는 것을 말한다. GraphSAGE의 핵심적인 특징은 aggregate function (aggregator)이 learnable하다는 것이다. 학습 가능한 aggregator를 사용함으로써 우리가 여태까지 보지 못했던 unseen node들에 대한 embedding도 얻을 수 있게 되고, 이에 따라서 inductive setting에서의 문제를 푸는 것도 가능해진다. 또한 aggregator는 permutation invariant한 특성 또한 가지는 것이 좋지만 필수적이지는 않다.
Aggregator의 대표적인 예시로는 mean, max pooling이 있다. 이들은 각각 아래 식들로 표현될 수 있다. 각 식에서 W는 학습 가능한 weight를 의미한다.
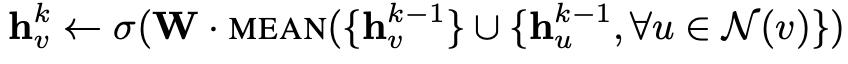
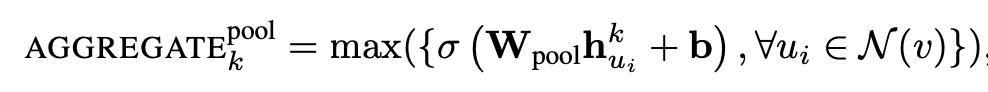
여기서 aggregator를 학습 가능하지 않은 hash function으로 대체하면 GraphSAGE 알고리즘은 WL test와 같은 알고리즘이 된다.
학습과 loss function
다음으로, GraphSAGE가 나타내는 node representation을 학습하는 loss function에 대해 알아보겠다. GraphSAGE는 모든 label이 주어지지 않은 unsupervised setting에서도 loss의 정의가 가능하게 하여, inductive setting에서도 node classification이 쉽게 가능하게 하였다.
이는 그래프 내에서 가까이 위치한 노드들의 representation을 최대한 비슷하게 만들고, 멀리 위치한 노드들의 representation을 최대하 다르게 만드는 것을 통해 정의된다. 이 loss function 식은 다음과 같다.

위 식에서 v는 노드 u와 어떤 특정 길이의 random walk 안에 도달할 수 있는 노드들, $p_n(v)$는 이의 negative sampling, 그리고 Q는 negative sample의 개수를 의미한다.
Experiments
GraphSAGE의 성능은 node classification 실험을 통해 측정되었고, 그 결과는 다음과 같다. F1 score가 높을수록 node classification을 더 잘했다고 할 수 있고, GraphSAGE가 기존의 graph representation learning 방법들보다 좋은 성능을 보였음을 알 수 있다.

이번 글에서는 GraphSAGE에 대하여 알아보았다. 다음 글에서는 또 다른 GNN 아키텍쳐인 GAT(Graph Attention Network)에 대해 알아보겠다.
References
1. Hamilton, W., Ying, Z., & Leskovec, J. (2017). Inductive representation learning on large graphs. Advances in neural information processing systems, 30.








최근댓글