RLHF는 reinforcement learning from human feedback의 줄임말로, 학습을 데이터셋에만 의존하지 않고 사람의 피드백을 강화학습에 결합하여 사람의 생각과 리워드 모델의 결과가 일치하도록 하는 것을 말한다. 이러한 RLHF는 처음에 language model을 optimize하는 방법으로 제시되어, ChatGPT의 성능을 올리는 데에도 활용되었다고 알려져 있다. 이번 글에서는 이 RLHF가 무엇인지에 대해 알아보겠다.
Motivation
옛날의 ChatGPT 버전에게 "세종대왕 맥북 던짐 사건이 뭔지 알려줘." 라고 요구하면, 세종대왕이 훈민정음을 쓰다가 담당자에게 분노하여 맥북프로와 함께 담당자를 던져 버렸다는 이야기를 말해준다는 밈이 있었다.

이런 글이 만들어졌을 때, 사람이라면 이를 보고 당연히 잘못된 글이라는 것을 판단할 수 있다. 하지만 데이터셋을 활용하여 supervised learning으로 학습된 생성 모델은 이를 스스로 판단할 수 없다는 한계점을 가진다.

그렇다면 사람은 이러한 것이 잘못되었다 혹은 다른 것이 더 좋다, 신뢰할 수 있다고 판단할 수 있는 능력을 갖추었으니, 이러한 사람의 생각을 모델이 따르도록 학습하면 저런 말도 안 되는 글이 생성되는 것을 막을 수 있지 않을까? 이러한 아이디어에서 출발한 연구가 바로 RLHF이다.
Method
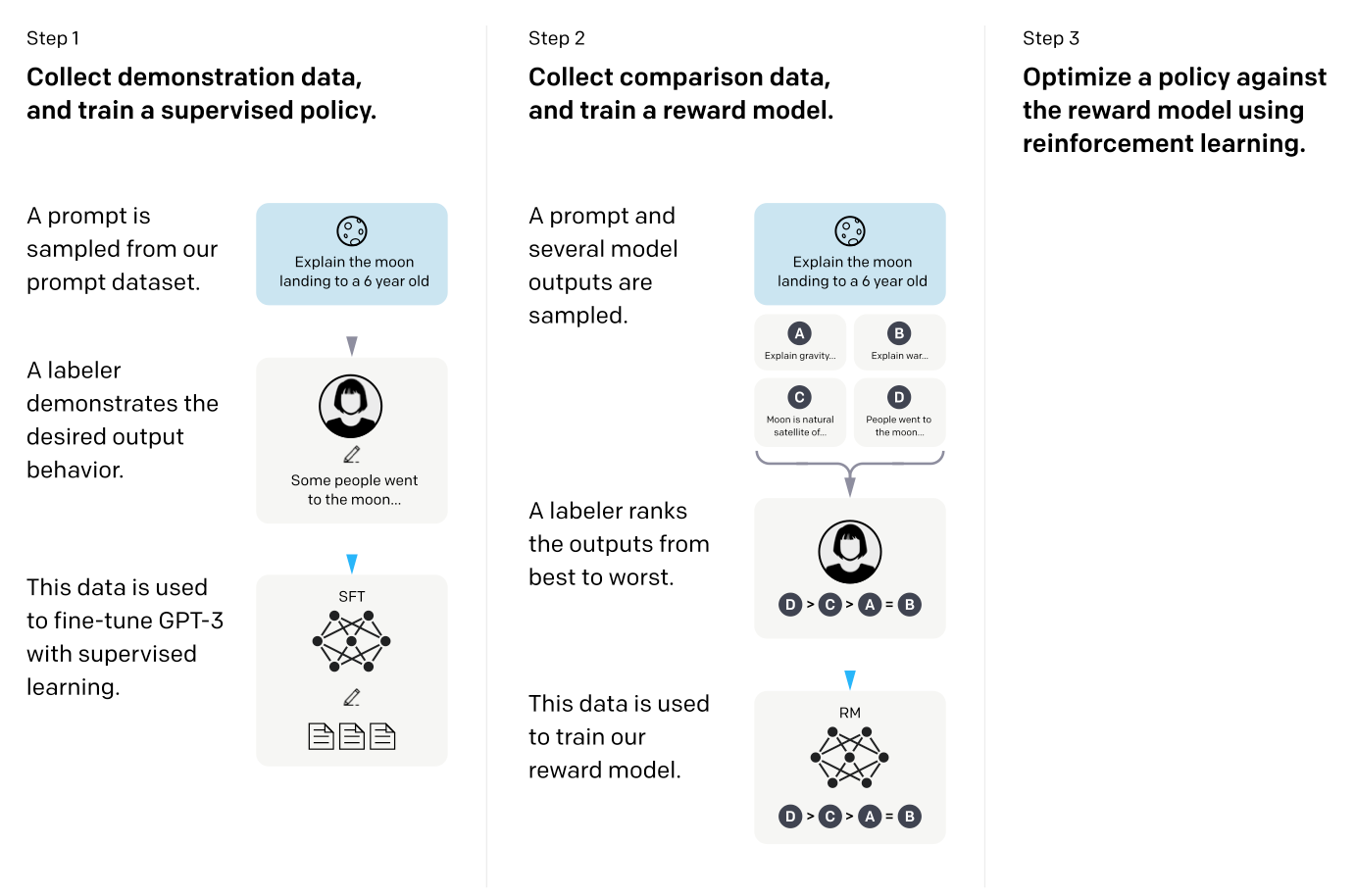
RLHF는 1) supervised fine-tuning (SFT), 2) reward model training, 3) RL with trained reward model의 세 단계로 이루어진다. 한 줄로 요약하면, 1) 우선 어떤 query가 주어졌을 때 그럴듯한 대답을 생성하는 모델을 학습하고 (SFT), 2) 이를 사람의 피드백을 반영할 수 있도록 fine-tuning하여 이를 기반으로 reward를 모델링하고, 3) 마지막으로 이 학습된 reward를 maximize하는 방향으로 RL을 진행하는 것이다. 이러한 과정을 통해 모델은 사람의 선호를 따르도록 학습된다. 그럼 이제부터 각 단계들에 대해 구체적으로 살펴보겠다.
Supervised fine-tuning (SFT)
Supervised fine-tuning은 데이터셋들을 기반으로 어떤 query q가 주어졌을 때 이에 따라 원하는 대답 $x_0$을 생성할 수 있도록 모델 $p_\theta$을 학습하는 과정이다. 우리는 여기에서 학습되는 모델 $p_\theta$를 policy라고 부르겠다.
이 때, generative model로는 어떤 모델이든 활용될 수 있지만 RLHF 논문에서는 pre-trained language model (GPT-3)을 활용하였다. 하지만 이러한 SFT의 문제점은 앞서 설명했듯이 사람의 선호를 반영하지 못하고 데이터셋만을 충실하게 학습할 수밖에 없다는 점이다.
Reward model training
SFT의 이러한 문제를 해결하기 위해 reward model training 단계에서 사람의 선호를 반영할 수 있는 학습을 진행한다. 만약 사람이 세종대왕 맥북 던짐 사건에 대해 GPT가 설명한 글을 보고, 별로라고 피드백을 준다고 하자. 그러면 이 피드백에 따라 모델은 세종대왕 맥북 던짐 사건에 대해 그렇게 대답하는 것에 대한 reward를 줄이는 방향으로 policy를 학습하는 것이다. 즉, reward를 maximize할 수 있는 방향으로 policy를 학습하게 된다. 이를 식으로 나타내면 다음과 같다.
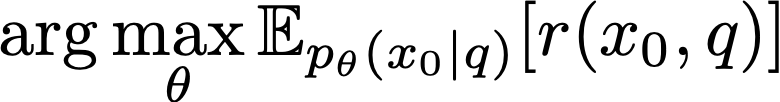
그렇다면 사람의 피드백을 어떻게 reward에 적절하게 반영할 수 있을까? 만약 사람이 주어진 글들에 대해 100점, 70점 이렇게 숫자로 점수를 매긴다고 하자. 그러면 이를 기억하기도 어렵고, 적절하게 점수를 매기기가 쉽지 않을 것이다. 그러므로 점수를 absolute하게 매기는 것이 아니라, 두 개의 선택지가 주어졌을 때 어떤 것이 더 나은지를 판단함으로써 reward를 학습한다. 다음으로, 모든 주어진 글들을 사람이 다 평가하는 것은 비용 측면에서 비효율적이다. 이를 해결하기 위해 모든 것을 사람이 비교하는 것이 아니라, 일부는 사람이 판단해놓고 이 선호 데이터를 기반으로 학습한 proxy 모델을 활용한다. 우리의 proxy 모델을 $p_\delta$, 선호 데이터셋(preference dataset)을 D라고 할 때, proxy 모델의 다음과 같은 식을 따른다.
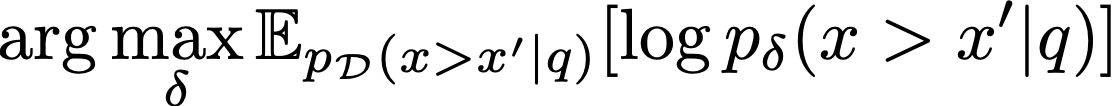
이러한 proxy 모델의 선호를 reward의 차이로 표현하면 다음과 같이 표현할 수 있다.

그러면 우리의 최종 reward 모델의 학습은 다음 식을 따라서 이루어질 것이다.

RL with trained reward model
마지막으로, 이렇게 학습된 reward 모델을 활용해서 강화학습을 통해 policy를 학습해야 한다. 이는 다음과 같은 식으로 표현될 수 있다.

하지만 이렇게 reward만을 최대화하는 방향으로 모델을 학습하면 local maxima에 빠질 수 있다는 문제가 있다. 이를 해결하기 위해 KL penalty를 적용한 PPO를 활용하여, 이를 최대한 방지해준다. 따라서 우리의 RLHF의 최종적인 학습 objective는 다음과 같다.

위 학습 objective를 좀 더 구체적으로 설명하면, 첫 번째 term은 위에서 설명했던 reward를 최대화하는 역할을 하고, 두 번째 term은 soft-RL에서의 entropy의 역할을 하여 exploration을 돕고, 마지막 세 번째 term은 SFT 모델(이후 단계에서는 변하지 않은, 최초의 SFT 모델)을 따르는 데이터가 만들어질 수 있도록 하여 완전히 말도 안 되는 데이터가 생성되는 것을 방지한다.
Experiments
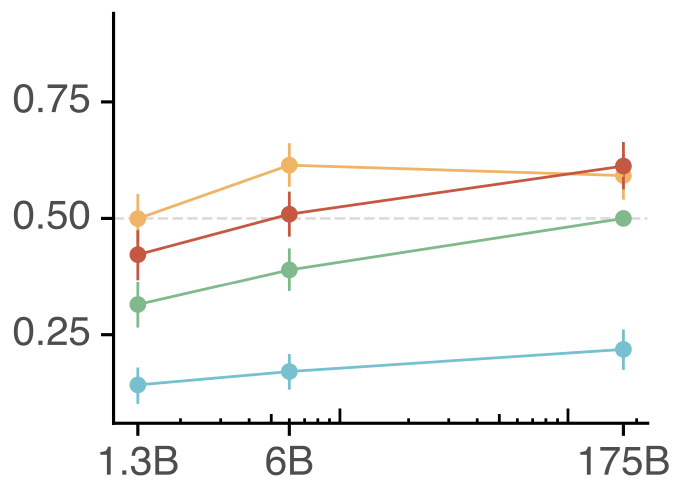
이러한 RLHF는 LLM의 성능 향상에 큰 기여를 했다. 아래 그림에서 노란색과 빨간색이 RLHF를 적용한 것, 초록색이 SFT만 한 것, 그리고 파란색은 그냥 GPT인데 RLHF가 SFT보다 훨씬 성능이 높은 것을 확인할 수 있다.
RLHF는 원래 제시되었던 LLM의 성능을 향상시키는 것 외에도 이미지 생성 등 다양한 분야에서도 성능 향상을 보였다고 한다. 이번 글에서는 RLHF가 무엇인지에 대해 알아보았다.








최근댓글