첫 데이터 마이닝 포스팅이다. 데이터 마이닝은 관련 포스팅이 너무 많기도 하고, 나보다 잘 아시고 글 잘 쓰시는 분들이 세상에 차고 넘칠 것 같아 (아 물론 프로세스 마이닝도 나보다 세상에 잘 아시는 분들이 차고 넘침) 이를 따로 쓸지 말지 고민을 좀 했는데, 각 데이터 마이닝 방법들이 프로세스 마이닝과 어떻게 연관되어 있는지를 설명하기 위한 밑바탕으로 그냥 글을 쓰려고 한다. (그리고 방금 구글에 오늘의 주제를 검색하고 왔는데 마음에 드는 포스팅이 별로 없다 ㅎㅎ 물론 내 것도 남들에게 그렇게 보이겠지만.. 하하)
데이터 분석을 공부하는 사람이라면 누구나 한 번 쯤 들어보았을 예시가 있다. 바로, 마트에서 기저귀를 사 가는 사람들은 맥주를 같이 사간다는 예시이다. 이렇게 어떤 사건이 얼마나 자주 함께 발생하는지, 서로 얼마나 연관되어 있는지를 표시하는 것을 Association Rule이라고 한다. 이번 포스팅에서는 이 Association Rule에 대해 알아보겠다.
Association Rule의 3가지 척도
Association rule에는 사건이 얼마나 자주 함께 발생하는지를 측정할 수 있는 3가지 척도가 있다. support, confidence, lift가 그것이다.
Support
Support는 전체 경우의 수에서 두 아이템이 같이 나오는 비율을 의미한다. 즉, 다음과 같은 식으로 표현할 수 있다.

위 식에서 N은 전체 경우의 수, N_x^y는 x와 y가 동시에 일어난 경우의 수를 의미한다. 예를 들어, 우리가 차와 라떼를 주문한 고객이 머핀을 주문할 support 값을 구하고 싶다고 하자. 그러면 우리는 다음과 같은 식을 통해 support를 계산할 수 있다. 즉, 차, 라떼, 머핀을 동시에 구매한 경우의 수를 전체 경우의 수로 나눈 값이 support가 된다.

여기서 우리가 눈치챌 수 있는 것은 support는 x와 y의 순서를 바꾸어도 결과가 똑같이 나온다는 것이다. 즉, 머핀을 주문한 고객이 차와 라떼를 주문할 support 값도 위 식과 똑같이 계산할 수 있다. Support 값은 높으면 높을수록 관계가 더 의미있다고 할 수 있다.
Confidence
Confidence는 X가 나온 경우 중 X와 Y가 함께 나올 비율을 의미한다. 즉, 구매의 경우를 예로 들자면 X를 산 사람 중에 Y도 같이 사는 사람의 비율을 말한다. 이는 다음과 같은 식으로 표현할 수 있다.
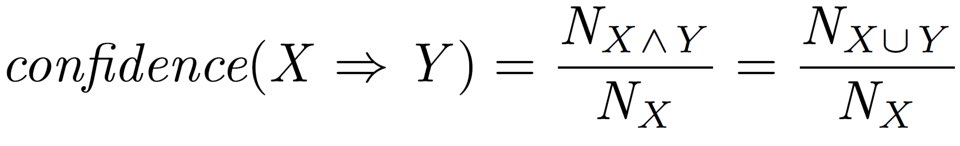
위 식에서 N_x는 x가 나온 경우의 수, N_x^y는 x와 y가 동시에 일어난 경우의 수를 의미한다. 위에서 든 예시와 똑같이 , 우리가 차와 라떼를 주문한 고객이 머핀을 주문할 confidence 값을 구하고 싶다고 하자. 그러면 우리는 다음과 같은 식을 통해 confidence를 계산할 수 있다.

Confidence 값은 1에 가까울수록 관계가 더 의미있다고 할 수 있다.
Lift
Lift는 X와 Y가 같이 나오는 비율을 X가 나올 비율과 Y가 나올 비율의 곱으로 나눈 값이다. 즉, 다음과 같은 식으로 표현할 수 있다.

또 다시 우리가 차와 라떼를 주문한 고객이 머핀을 주문할 lift 값을 구하고 싶다고 하자. 그러면 우리는 다음과 같은 식을 통해 lift를 계산할 수 있다.

Lift 값은 1보다 높을 때 positively correlation, 1일 때 independent, 1 a미만일 때 negatively correlation이라고 여긴다. 그렇기 때문에 lift 값을 1보다 높은 값을 가질 때 관계가 의미있다고 할 수 있다.
Association Rule을 찾는 방법
위 3가지 척도를 이용해서 데이터셋으로부터 의미있는 association rule을 만들어내려면 어떻게 해야할까? 이에는 brute force, apriori algorithm, FP-growth algorithm 등 여러 가지 방법이 있을 수 있다. 가장 간단한 brute force 방식만 여기서 소개하도록 하겠다.
Brute Force
Brute Force는 말 그대로 모든 rule들을 살펴보는 것이다. 이는 다음과 같은 과정을 통해 이루어진다.
1. 모든 frequent item set을 만든다.
모든 아이템들(위 예시로 치면 tea, latte, muffin 등) 중 두 번 이상 나왔고, minsup (support 값의 최소 기준(threshold)) 값을 넘는 아이템들을 찾는다.
2. 1에서 찾은 frequent item set에 대해 만들 수 있는 모든 association rule들을 만들고, 이들 중 minconf(confidence 값의 최소 기준(threshold))값을 넘는 rule들을 찾는다.
Brute Force 방식으로 1의 모든 아이템 셋들에 대해 rule을 찾는다.
3. 완성!
하지만 위 방식은 너무 많은 아이템들에 대해 너무 많은 rule들을 확인해야 하기 때문에 비효율적이고, 결과에서 너무 많은 rule들이 도출될 수 있다는 단점을 가진다. 이 단점을 극복하기 위해 나온 알고리즘이 FP-growth 알고리즘이다. 이는 다음 포스팅을 참고한다.
2019/11/29 - [Data Mining - Thoery] - FP-Growth 알고리즘이란? (FP-growth algorithm이란
FP-Growth 알고리즘이란? (FP-growth algorithm이란
Association Rule의 적용을 위해서는, 각 item들이 각 itemset 안에서 어떤 빈도로 출연했는지, 어떤 item과 함께 나왔는지를 세는 것이 필수적이다. (Association Rule이 무엇인지 궁금하다면 다음 포스팅을 참고..
process-mining.tistory.com
이번 포스팅에서는 Association Rule이 무엇인지, 그리고 이 Association rule을 도출할 수 있는 가장 쉬운 방법인 brute force 방식에 대해 알아보았다. 다음 포스팅에서는 association rule이 process mining과 어떻게 연관될 수 있는지, 그리고 association rule을 도출할 수 있는 다른 알고리즘에는 어떤 것이 있는지에 대해 알아볼 것이다.
2019/08/04 - [Process Mining & Data Mining] - Sequence Mining이란?
Sequence Mining이란?
Association Rule은 어떤 아이템과 다른 아이템의 연관성을 찾는 것을 목표로 한다. 하지만 Association Rule은 아이템들의 ordering은 고려하지 않는다는 한계점을 가진다. 즉, 내가 광어와 간장을 사면 와사비도..
process-mining.tistory.com
References
1. Course: Business Process Intelligence. Wil van der Aalst. RWTH








최근댓글