거의 한 달 만의 글이다. 그리웠던 일상 ㅠㅠ 집이 최고야~ 사실 일상으로 돌아온지는 좀 됐지만 체력 회복 기간이 필요했다...
Inductive Miner는 DFG를 기반으로 하여 cut을 찾아냄으로써 프로세스 모델을 찾아내는 알고리즘이다. 하지만 이 알고리즘에는 치명적인 단점이 하나 있는데, 바로 빈도를 고려하지 못한다는 것이다. 즉, 두 액티비티가 연결되어 있기만 하면 Directly follows 관계가 1번 일어났든 100번 일어났든 cut을 찾을 때 똑같은 취급을 당한다는 것이다. 이번 포스팅에서는 이러한 문제점을 해결하기 위해 등장한 알고리즘인 IMi 알고리즘에 대해 알아보겠다.
* 본 포스팅은 Inductive Miner에 대한 기본적인 지식이 있음을 전제로 한다.
2019/07/23 - [Process Mining - Theory/Process Discovery] - Inductive Miner란?
Inductive Miner란?
한 달 만의 글이다. 학회와 시험과 여행의 조합으로 이제야 일상으로 돌아왔다. 그리웠다... 20일 뒤에 또 시험인 것은 함정 ^_^ Inductive Miner는 Process Discovery 알고리즘 중 하나로, 이벤트 로그로부터 프..
process-mining.tistory.com
다음과 같은 예시 이벤트 로그와 함께 알고리즘에 대한 설명을 진행하겠다.

Inductive Miner의 적용
가장 먼저 해야 할 일은 기존의 Inductive Miner 알고리즘을 똑같이 적용하는 것이다. IMi 알고리즘은, 기존의 Inductive Miner과 같은 방식으로 Cut detection을 했는데 cut을 찾지 못할 때에 사용된다. 우선, 기존의 Inductive Miner를 적용하기 위해 DFG를 도출하면 다음과 같다.

위 DFG에서 우리는 cut을 찾을 수 없기 때문에 DFG의 필터링을 진행한다.
Filters on Operator & Cut Selection
이 단계에서는 빈도가 낮은 directly follows relation을 필터링함으로써 새로운 cut을 찾을 수 있도록 도와준다. 이 때, 필터링의 기준이 되는 상수 k를 정의한다. k는 0과 1 사이의 값으로, 가장 높은 빈도의 directly follows relation에 k 값을 곱한 것보다 빈도가 작은 모든 directly follows relation을 제거한다. 예를 들어, k가 0.1이라고 하자. 우리의 예시에서의 빈도의 최댓값은 a>b의 200이고, 이에 따라 200*0.1=20보다 빈도가 낮은 directly follows relation인 e>d(빈도: 1)를 제거한다. 이러한 방식을 Heuristics-style filtering이라고 한다.
이렇게 e>d 관계를 제거하면 다음 점선과 같이 sequence cut을 찾을 수 있다.

이러한 방식으로 cut detection을 진행해나갈 수 있다. 그렇다면 cut을 찾은 이후에 log projection은 어떤 방식으로 진행될까?
* 다른 필터링 방식인 eventually-follows graph 기반 필터링도 있지만, 글이 너무 복잡해질 것 같아 생략한다. 자세한 것은 논문을 참고하면 된다.
Filters on Log Splitting
이 단계에서는 log projection을 진행한다. 기존의 Inductive Miner는 frequency를 고려하지 않았기 때문에 나눠진 cut의 액티비티 종류만을 기준으로 하여 log projection을 진행하면 됐다. 하지만 IMi에서는 infrequent relation을 무시하고 cut을 나누었기 때문에 log에는 해당 infrequent activity가 남아 있을 수 있다. 이를 위해서 IMi에서는 log projection을 다음과 같이 진행한다.
다음과 같은 cut을 찾았다고 가정한다.

XOR Cut
XOR Cut을 찾은 경우, 각 trace에 대해서 가장 잘 맞는 cut에 대해서 projection을 한다. 예를 들어, 다음과 같은 trace가 있다고 하자.

이 trace가 {a}에 대해 projection되는 것이 더 적합할까 {b}에 대해 projection되는 것이 더 적합할까? {a}에 대해 projection되면 b 액티비티 하나만 사라지면 되지만, {b}에 대해 projection 되면 대부분의 a 액티비티가 사라져야 하기 때문에 {a}에 대해 projection되는 것이 더 적합할 것이다. 그렇기 떄문에 {a}에 대해 projection을 진행하고, 이에 따라 새로 만들어진 trace는 다음과 같을 것이다.

Sequence Cut
Sequence Cut을 찾은 경우, trace를 mistmatch가 가장 적은 방향으로 나눈다. 예를 들어, 다음과 같은 trace가 있다고 하자.

이 trace를 두 개의 cut에 대해 나누어 보면, <>, <a,a,a,a,b,b,b,b,a,b> / <a>, <a,a,a,b,b,b,b,a,b> / <a,a>, <a,a,b,b,b,b,a,b> / ... / <a,a,a,a,b,b,b,b,a,b>, <> 로 나눌 수 있다. 이 때, 각 나누어진 trace에 대해서 각 cut들과의 mismatch를 비교해보면, 첫 번째 trace는 <a,a,a,a,b,b,b,b,a,b>에서 {b}에 속하지 않는 액티비티(mismatch)가 5, 두 번째 trace는 <a>는 {a}에 모두 속하기 때문에 mismatch가 0, <a,a,a,b,b,b,b,a,b>는 4 등으로 모두 계산할 수 있다. 이렇게 mismatch를 계산한 후 가장 mismatch가 작은 방향으로 log를 projection한다. 우리의 예시에서는 <a,a,a,a>, <b,b,b,b,a,b>가 mismatch가 1로 가장 작고, 이를 projection하면 다음과 같다.
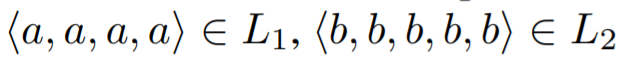
Parallel Cut
Parallel Cut은 그것의 subtree 안에 있는 액티비티의 모든 behavior를 허용하는 operator이기 때문에 infrequent cut을 삭제하는 것에 대해서 영향을 받지 않는다. 그러므로 기존의 IM과 똑같이 projection을 진행한다.
Loop Cut
Loop Cut은 loop body로 시작하거나 끝나지 않는 trace에 의해 violate된다. 그러므로 invalid한 start와 end를 가지는 trace에 대해서 첫 번째 projection 로그에 empty trace를 추가한다. 예를 들어, 다음과 같은 trace가 있다고 하자.

우리의 cut은 loop body가 {a}이고 뒤 것이 {b}이기 때문에 a로 끝나거나 시작되지 않는 위 trace는 이 loop cut을 violate한다. 그러므로 {a}에 projection되는 것에 대해 empty trace를 추가한다. 그 결과는 다음과 같다.

Filters on Base Cases
기존의 IM은 base case가 찾아지면 cut을 찾는 것을 종료했고, 이는 IMi에서도 똑같이 적용된다. 하지만 IM과의 차이점은 empty trace가 projection된 log에 나타날 수도 있다는 점이다. 예를 들어, 다음과 같은 이벤트 로그가 있다고 하자.

이에 대한 DFG를 그려 cut을 찾으면 sequence cut을 찾을 수 있다. (자세한 과정은 생략한다.) 그리고 이는 다음과 같이 log projection될 것이다.

이 경우, empty trace는 한 번밖에 일어나지 않았기 때문에 L2는 b와 c의 xor cut으로 projection하는 것이 더 좋을 것이다. 하지만 만약 empty trace가 100번 일어났다면, 이는 무시할 수 없다. 그럴 때에는 이를 b, c, invisible transition의 xor cut으로 projection한다. 이 때, 빈도의 기준은 k에 의해 결정된다.
위와 같은 방식으로 IM과 같이 이벤트 로그에 대해 recursion을 반복함으로써 frequency를 고려하여 petri net을 얻을 수 있다. IMi 알고리즘을 이용하여 많은 기본적인 process discovery 알고리즘들이 해결할 수 없는 문제인 infrequent behavior를 필터링함으로써 더 좋은 성능의 프로세스 모델을 도출할 수 있을 것이다.
References
1. Leemans, S.J.J., Fahland, D., van der Aalst, W.M.P.: Discovering block-structured process models from event logs containing infrequent behaviour. In: International Conference on Business Process Management. pp. 66–78. Springer (2013)








최근댓글