한 달 만의 글이다. 학회와 시험과 여행의 조합으로 이제야 일상으로 돌아왔다. 그리웠다... 20일 뒤에 또 시험인 것은 함정 ^_^
Inductive Miner는 Process Discovery 알고리즘 중 하나로, 이벤트 로그로부터 프로세스 트리를 도출하는 알고리즘이다. (프로세스 트리가 무엇인지 모른다면 다음 포스팅을 참고하도록 한다.)
2019/06/23 - [Theory/Process Model] - Process Tree란?
Process Tree란?
Process Tree란, 트리 구조를 이용한 프로세스 모델 language이다. 트리 구조를 가지기 때문에 각 노드(액티비티)가 어떤 관계를 가지고 있는지를 한 번에 파악할 수 있다는 장점을 가진다. 또한 프로세스 트리는,..
process-mining.tistory.com
Inductive Miner는 결과물로 프로세스 트리를 도출하기 때문에, 결과 프로세스 모델이 soundness를 보장한다. 그렇기 때문에 최근 가장 주목 받고 있는 process discovery 알고리즘 중 하나이다. 이번 포스팅에서는 inductive process discovery, 그 중에서도 가장 기본적인 IM 알고리즘이 무엇인지에 대해 알아볼 것이다.
DFG(Directly Follows Graph)
우선 이벤트 로그 예시를 하나 들도록 하겠다.

가장 먼저 해야 할 일은 이벤트 로그로부터 DFG를 도출하는 것이다. 이를 잘 모르겠다면, 이 포스팅을 참고하도록 한다.
2019/06/21 - [Theory/Process Model] - DFG(Directly Followed Graph)란?
DFG(Directly Followed Graph)란?
Directly Followed Graph란, 각 액티비티 간의 directly follow 관계 (a->b)만을나타낸 그래프를 말한다. 이는 가장 널리 쓰이는 Process Discovery 방식 중 하나인 Inductive Miner를 사용할 때에 기본이 된다...
process-mining.tistory.com
우리의 예시 이벤트 로그로부터 DFG를 도출하면 다음과 같다.
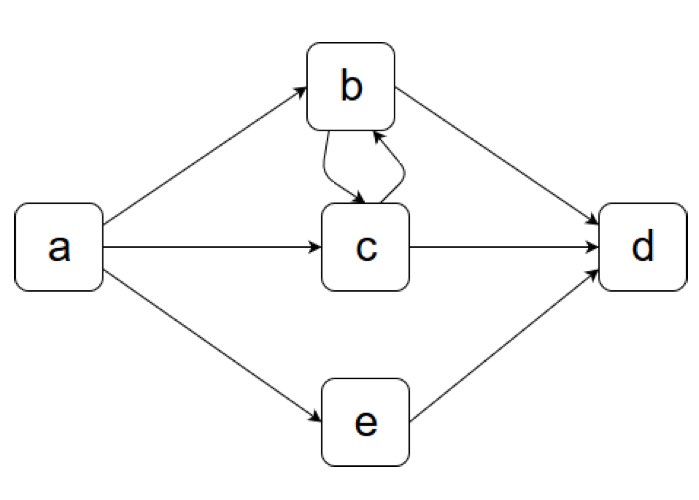
G(L) 도출
다음으로, G(L)을 도출한다. (G(L)은 정의에 따라서 inductive miner를 도출할 것이 아니라, 그림으로 이해만 할 것이라면 넘어가도 된다. 시작 액티비티와 끝 액티비티를 표현하는 부분만 이해하면 된다.) G(L)은 다음과 같이 정의할 수 있다.

와.. 얘 또 수학하네... 아님. 아닙니다. 수학 아닙니다... 흑흑 우리의 이벤트 로그를 다시 보자.
A_L은 모든 액티비티의 리스트를 말한다. 즉, 우리의 이벤트 로그에서는 {a, b, c, d, e}이다.
->_L은 모든 direct succession(x>y)을 말한다. 우리의 이벤트 로그에서는 {a>b, a>c, a>e, b>c, b>d, c>b, c>d, e>d}이다.
A^s_L (수식이 더러운 것은 양해를.. 티스토리는 수식을 넣으면 줄이 바뀐다 ㅠㅠ)는 모든 트레이스에 대해 시작하는 앧티비티를 말한다. 우리의 이벤트 로그에서는 모든 트레이스가 a로 시작하므로 {a}이다.
A^e_L은 모든 트레이스에 대해 끝나는 액티비티를 말한다. 우리의 이벤트 로그에서는 모든 트레이스가 d로 끝나므로 {d}이다.
이를 이용하여 시작하는 액티비티와 끝나는 액티비티까지 DFG에 함께 표현해준다. 그러면 아래 그림과 같이 DFG에 시작하는 액티비티인 a에 들어가는 화살표(시작 표시), 끝나는 액티비티인 d에 나가는 화살표(끝 표시)가 추가된다.

알고리즘의 적용 (Inductive Miner)
이 부분에서 Inductive라는 이름이 왜 붙었는지를 알 수 있다. 우선 우리는 base case라는 것을 정의한다. base case란, 액티비티 1개로 이루어졌거나 silent activity로만 이루어진 이벤트 로그를 의미한다.
DFG(L) 도출
우선, 이벤트로그로부터 도출한 DFG에 G(L) 정보가 추가된 것을 본다.
이것이 base case인가? 액티비티 5개로 이루어져 있다. 명백하게 아니다. 그렇다면 다음 단계로 넘어 간다.
Cut 찾아내기
Cut에는 exclusive-choice cut, sequence cut, parallel cut, loop cut의 4가지 종류가 있다. Cut을 찾을 때에는, 앞에 쓰여진 순서대로 cut이 있는지 없는지를 확인하도록 한다. 이 cut들의 정의만 쓰면 또 모두가 싫어하는 수학 같아 보일 것이기 때문에 그림과 함께 표현하도록 하겠다. 여기서 수학적 정의에 익숙하지 않은 사람에게는 설명이 조금 어려워보일 수 있는데, 그림을 통해서 느낌만 받아 들이고 예시를 설명하는 부분을 먼저 보는 것이 이해가 더 쉬울 수도 있다.
1. Exclusive-Choice Cut을 찾는다.
Exclusive-Choice (XOR) Cut은 쉽게 이야기 하면 연결되지 않은 덩어리를 의미한다. 아래 그림에서, 시그마1과 시그마2 사이에 서로 연결된 화살표가 없다면 (빨간 엑스에 해당하는 화살표가 없어야 함) 이는 exlusive-choice cut이라고 할 수 있다.

이를 정의로 나타내면 다음과 같다. 즉, 각 partition (A1, A2, ...)에 대해서 connection이 아예 없는 partition들은 서로 Exclusive-Choice cut 관계이다.

2. Sequence Cut을 찾는다.
Exclusive-Choice Cut이 없다면 다음으로는 Sequence Cut을 찾는다. Sequence Cut은 각 Partition 사이에서 한 방향으로만 화살표가 있는 것을 의미한다. 아래 그림에서, 시그마1에서는 다른 partition으로 나가는 방향의 화살표만 있고, 빨간 엑스에 해당하는 1로 들어가는 방향의 화살표는 없다. 이러한 경우에 이를 sequence cut이라고 할 수 있다.

이를 정의로 나타내면 다음과 같다. 즉, 파티션 내의 구성요소들이 한 방향으로만 연결되어 있고, 반대 방향의 연결은 존재하지 않는 것을 의미한다. 이 때, 모든 각 구성 요소의 pair에 대해 다음 액티비티로 갈 수 있는 path가 존재해야 한다.

3. Parallel Cut을 찾는다.
Sequence Cut도 없다면 다음으로는 Parallel Cut을 찾는다. Parallel Cut은 두 가지 조건을 가진다. 먼저, 각 partition마다 start activity와 end activity가 모두 포함되어야 한다. 다음으로, partition 내의 각각의 element(액티비티) 쌍에 대해서 이들이 서로 양 방향으로 모두 연결되어 있어야 한다. 아래 그림과 같이, 1과 2에 시작, 끝 액티비티가 모두 포함되어 있고 각 element들이 모두 양 방향으로 연결되어 있는 경우 이들을 parallel 관계라고 한다.

이를 정의로 나타내면 다음과 같다. 위에서 설명했듯이, 모든 파티션에 대해 start activity와 end activity가 각각 한 개 이상씩 포함되어 있고, 모든 element 쌍에 대해서 양방향으로 directly followed 관계가 존재해야 한다.

4. redo-loop Cut을 찾는다.
Parallel Cut도 없다면 다음으로 redo-loop Cut을 찾는다. Loop Cut은 그림으로 보았을 때는 간단해 보이지만, 가장 많은 조건들을 가진다. 아래 그림에서는, 1과 2가 loop cut 관계이다.
그 조건들을 모두 설명하면 다음과 같다. 우선, partition 1이 모든 start와 end activity를 가진다. 다음으로, 1에서 다른 partition으로 가는 outgoing arc가 있으면, 해당 element는 end activity이다. 이와 비슷하게 다른 partition으로부터 1로 들어가는 incoming arc가 있으면 해당 element는 start activity이다. 다음으로, partition 1을 제외하고 다른 partition끼리는 connection이 없다. 마지막으로, 1에서 다른 partition으로 가는 outgoing arc가 있으면, 1에 포함된 모든 end activity는 다른 partition으로 가는 outgoing arc를 가진다. 이와 비슷하게, 다른 partition에서 1로 가는 ingoing arc가 있으면, 1에 포함된 모든 start activity는 다른 partition에서 오는 incoming arc를 가진다.
어렵게 보일 수 있는데, 한 문장 하나하나 떼어 보면 그렇게 어렵지 않다. (는 나도 처음에 어려웠다 하하..) 단순히 알고리즘을 이해하고 싶다면, 그림에서 start와 end 액티비티가 포함된 덩어리에서 그것이 없는 덩어리로 가는데 없는 덩어리끼리는 connection이 없는지를 확인한다. 그리고 나머지 조건들을 따져 주면 그나마 쉽게 loop cut을 찾을 수 있다.

위에서 장황하게 설명한 것을 수학적 정의로 나타내면 다음과 같다. (순서를 똑같이 설명했다.)

Cut을 실제로 찾아 보기 위해 우리의 예시로 다시 돌아가자.
exclusive-choice cut, sequence cut, parallel cut, loop cut의 순서를 기억하자!
exclusive-choice cut이 있는가? 즉, 따로 혼자 떨어진 것이 있는가? 없다.
sequence cut이 있는가? 즉, 한 방향으로만 가는 액티비티가 있는가? 있다. a를 partition 1이라고 하고, d를 partition 2, 나머지를 partition 3이라고 하면, partiiton 1에서는 partition 3으로 가기만 하고, 반대 방향의 연결은 없고, partition 3에서는 partition 2로 가기만 하고, 반대 방향의 연결이 없다. 저 곳을 잘라 준다.

그러면, 다음과 같이 프로세스 트리가 만들어진다.

이를 process tree 그림으로 만들면 다음과 같다.

이제, 이를 바탕으로 하여 우리의 이벤트 로그를 각 partition에 대해 해당 액티비티만 포함된 로그로 바꾼다.
우선, partion 1은 {a}이기 때문에, 이것만 포함된 로그로 L_1을 바꾸면, 다음과 같다.

partition 2는 {d}이기 때문에, 이를 바꾸면 다음과 같다.

partition 3는 {b,c,e}이기 때문에, 이를 바꾸면 다음과 같다. 이 때, 로그 내의 액티비티의 순서는 그대로 유지해야 한다.

이제, 이 나누어진 로그에 대해 위의 과정(base case 판별하기, DFG 그리기, cut 찾기)을 다시 반복한다.
L_partition1과 L_partition2는 base case이기 때문에 더 이상의 과정이 필요 없다. L_partition3에 대해 directly followed graph를 다시 그리면 다음과 같다.

다시 cut을 찾는다. XOR cut이 있는가? 있다. e가 혼자 떨어져 있다.

그러면, 다음과 같이 process tree가 만들어진다.

이를 process tree 그림으로 만들면 다음과 같다. 이것이 위의 프로세스 트리 그림에서 {b,c,e} 부분에 해당하는 것이다.

이를 위 프로세스 트리와 합하면 다음과 같다.
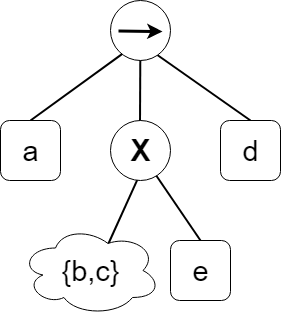
이제 위에서 한 과정을 또 반복한다. e가 base case인 것은 명백하기 때문에, e에 대한 로그를 도출하는 것은 생략하고, b, c에 대해서만 하도록 하겠다. 이의 로그를 다시 만들면 다음과 같다.

이 로그를 바탕으로 DFG를 만들면 다음과 같다.
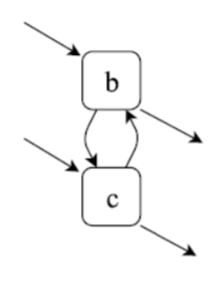
여기서 cut을 다시 찾는다. XOR cut이 있는가? 없다. sequence cut이 있는가? 없다. parallel cut이 있는가? 이 말은 위에서도 말했지만, 나누었을 때 각 partition에 start와 end activity가 모두 포함되고, 각 element들이 모두 양방향으로 연결되어 있는가? 라는 의미이다. b, c를 나누었을 때 조건을 만족하는 것을 알 수 있다. 있다!

그러면 다음과 같이 process tree가 만들어진다.
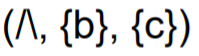
이를 그림으로 나타내면 다음과 같다.

이를 위에 만들어져 있던 process tree와 합하면 다음과 같다.

모든 로그가 base case이기 때문에 종료한다. process tree가 완성되었다!
맺음말
기나긴 여정이었다.... Inductive Miner는 프로세스 모델이 soundness를 보장하고, 모델의 quality도 좋은 경우가 많아 현재 가장 널리 쓰이는 process discovery 알고리즘이다. 그래서 설명이 고난과 역경의 길일 것임을 알면서도 무리해서 설명했다. 정의가 많고, 수학 같아 보이는 것도 많아서 조금 복잡해 보일 수도 있는데, 익숙해지면 그렇게 어렵지 않다.
혹시 여기서 "cut을 못 찾으면 어떻게 되지?" 라는 의문이 들지는 않는가? cut을 찾지 못하면 FallThrough라는 과정을 한 번 더 거쳐 이를 처리해주어야 한다. 이것까지 설명하면 글이 너무 길어지기 때문에, 다음에 설명하도록 하겠다.
References
1. Wil van der Aalst. Process Mining: Data Science in Action (Second Edition) : Springer, 2016.
2. Course: Advanced Process Mining. RWTH. Dr.ir. Sebastiaan J. van Zelst








최근댓글