Precision과 Recall은 데이터 마이닝에서 어떤 값을 예측하는 모델의 성능을 평가할 때 아주 흔하게 쓰이는 개념이다. 이번 포스팅에서는 이 precision과 recall이 프로세스 마이닝에서는 어떻게 계산되는지에 대해 알아보겠다.
데이터 마이닝에서의 precision과 recall
우선, 데이터 마이닝에서의 precision과 recall에 대해 간단히 짚고 넘어가겠다. 이미 알고 있다면, 이 부분은 건너 뛰어도 좋다. 우리가 어떤 값을 예측하는 모델을 만들었고, 이 모델을 테스트한다고 하자. 우리는 정답 데이터(actual class)와 우리의 모델이 예측한 데이터(predicted class)를 비교함으로써 얼마나 맞았고, 얼마나 틀렸는지를 평가할 수 있을 것이다.

이 때, 우리는 이것이 맞고 틀리고의 여부에 따라 데이터를 네 종류로 분류할 수 있다.
- TP (True Positive): +로 예측했고, 실제로 +인 것. 맞게 예측한 것이다.
- TN (True Negative): -로 예측했고, 실제로 -인 것. 맞게 예측한 것이다.
- FP (False Positive): +로 예측했지만 실제로는 -인 것. 틀리게 예측한 것이다.
- FN (False Negative): -로 예측했지만 실제로는 +인 것. 틀리게 예측한 것이다.
당연히 우리는 TP와 TN, 즉 맞게 예측한 것이 많고 FP와 FN, 즉 틀리게 예측한 것이 적을수록 행복할 것이다. 이를 수치로 표현한 것이 precision과 recall이다. Precision과 Recall은 다음과 같은 식을 통해 계산할 수 있다.

혹시나 이것을 외워야 하는 시험을 준비하는 대학생이거나 대학원생이라면..! 나도 옛날에 이게 시험칠 때마다 헷갈렸는데 누가 전에 이상한 방법을 알려줘서 그 이후로 안 까먹고 있다. 전혀 논리적이지 못한데 왠지 모르게 기억이 난다.... 진짜 이상한 방법이라고 생각했는데 분하다.... 처음과 끝 획이 가는 곳으로 기억하는 것이 포인트 (근데 이랬다가 actual이랑 predicted 방향 틀리면 망함)

프로세스 마이닝에서의 precision과 recall
프로세스 마이닝에서의 precision과 recall은 위에서 설명한 것과 비슷하다. 하지만 우리는 뚜렷한 target value를 가지고 있는 것이 아닌, 이벤트 로그로 이를 측정해야 한다. 그래서 우리는 각 TP, FN, TN, FP를 다음과 같이 정의한다.

- TP: desired behavior이며 모델로도 표현될 수 있는 경우
- TN: 예외적인(exceptional) behavior이고, 모델로는 표현될 수 없는 경우
- FP: 예외적인 behavior인데, 모델에 표현된 경우
- FN: desired vehavior이지만 모델로 표현될 수 없는 경우
약간 복잡하게 느껴질 수 있다. 하지만 그저 위에서 표현한 recall과 precision의 개념에서 discover한 프로세스 모델로 표현할 수 있는 것을 predicted value가 positive인 것이고, desired behavior인 경우에 actual value가 postivie한 것으로 나타낸 것이라고 생각하면 된다. 즉, 이를 이용해서 위에서 한 것과 똑같이 precision과 recall을 계산하면 다음과 같이 정의를 내릴 수 있다.

예시와 함께 이의 계산 방법에 대해 알아보겠다.
다음과 같은 이벤트 로그가 있고, 우리가 원하는 desired trace(TP)는 <a, c, e>라고 하자.

그리고 우리가 추정한 모델(descriptive model)이 다음과 같이 생겼다고 하자.
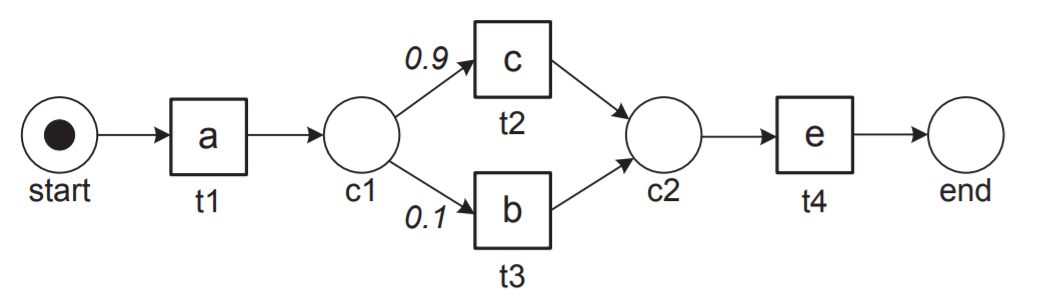
우선, 우리는 우리의 pi_L(TP) 값을 구할 수 있다. 이벤트 로그에서 <a, c, e>가 나오는 빈도를 계산하면 된다. 이는 16/20=0.8이다. 다음으로, 우리는 우리의 pi_1(TP) 값도 구할 수 있다. 우리의 descriptive model에서 <a, c, e>가 나올 수 있는 확률을 구하면 된다. 이는 0.9이다.

그리고 recall과 precision의 분모 값은 이벤트 로그의 trace들이 그 이벤트 로그 안에서 나타날 확률/ 각각 모델의 trace들이 그 모델 안에서 나타날 확률이므로 우리의 예시에서는 1이 된다. 그러므로 우리의 precision, recall 값은 다음과 같이 계산된다.
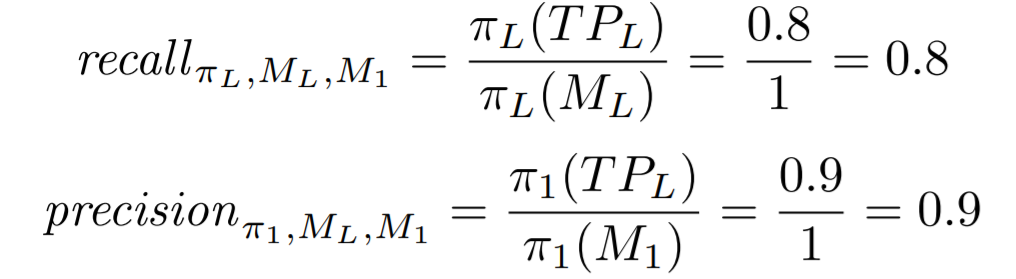
만약 우리가 모든 behavior들은 이벤트 로그에 나타날 수 있고 (all observed behavior is possible in M_L), 모델의 behavior를 제외한 다른 behavior가 모델에서 나타날 수 없다고 (behavior that is not modeled is considered to be impossible) 가정하면 우리의 precision과 recall 값을 다음과 같이 간단하게 나타낼 수 있다.


즉, precision은 프로세스 마이닝에서의 precision, recall은 프로세스 마이닝에서의 fitness와 같은 역할을 한다는 것을 알 수 있다. 이들에 대한 간단한 설명은 이 글에서 볼 수 있다.
이번 포스팅에서는 프로세스 마이닝에서의 precision과 recall이 어떻게 계산될 수 있는지에 대해 알아보았다. 저번 주까지 휴가 아닌 휴가가 생겨서 마음 편하게 글을 쓸 수 있었는데, 내일부터 일주일 동안은 다시 논문을 달려야해서 2019년 100개 포스팅이 가능할 지 모르겠다. ㅠㅠ (팩트: 누워서 요양하는 시간만 줄이면 가능함)
References
W.M.P. van der Aalst. Mediating Between Modeled and Observed Behavior: The Quest for the "Right" Process. In IEEE International Conference on Research Challenges in Information Science (RCIS 2013), pages 31 - 43. IEEE Computing Society, 2013.








최근댓글