Ridge regression은 linear regresssion에 regularizer를 추가하여 overfitting을 방지한 regression 방법으로, MAP estimation을 통해서 모델링을 한다는 특징을 가진다. 이번 포스팅에서는 Linear Regression에 이어 Ridge Regression(Penalized Least Squares)이 무엇이고 이것이 작동하는 수학적 원리가 무엇인지, 그리고 이것이 단순한 Linear Regression(Least Squares)에 비해 overfitting에 강한 이유에 대해 알아보겠다. 이번 포스팅은 maximum likelihood와 MAP estimation에 대한 이해가 있다고 가정한다.
Motivation
우리가 Least Squares를 이용한 단순한 regression을 이용해 다음과 같은 데이터를 예측하는 식을 모델링한다고 하자.

위 그림에서도 볼 수 있듯이, 데이터가 쉽게 말하면 위아래로 왔다갔다하기 때문에 이에 대한 w를 추정하면 w가 양수와 음수를 심하게 왔다갔다 할 것이다. (쉽게 말하면 이는 우리가 지난 Linear Regression 포스팅에서도 잠깐 보았듯이, Least squares에서는 w에 대한 prior를 uniform으로 주기 때문에, w가 오만 값으로 튈 수 있기 때문이다.) 이렇게 w 값이 크게 튀는 것을 방지하면 우리는 아래 그림과 같이 좀 더 overfitting되지 않은 모델을 만들 수 있을 것이다.

이를 위해 우리는 w 값이 크게 튀지 않는 prior를 w에 주고, 이를 바탕으로 posterior를 구해서 MAP estimation을 통해 regression을 진행할 것이다. 이러한 방법 중 하나가 Ridge Regression이다.
Ridge Regression
우선, 결론부터 얘기하면 Ridge Regression은 RSS를 최소화하면서 w의 L2 norm까지 최소화하는 것을 목적으로 한다. 이는 아래의 식을 최소화하는 w를 찾는 과정이다.
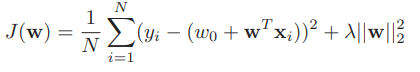
그렇다면 위의 식은 어떻게 도출된 것일까? 위에서도 설명했듯이 우리는 w 값이 uniform distribution보다 덜 튀는 분포를 w의 prior로 주고 싶다. 이러한 과정을 우리는 정규화(regularization) 혹은 weight decay라고 부른다. 이를 위해 우리는 w의 prior를 다음과 같은 평균이 0인 정규 분포로 정한다.
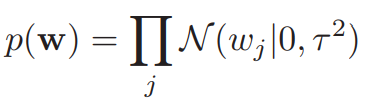
그렇다면 우리는 이 prior와 기존에 우리가 알던 정규 분포의 likelihood를 곱하고, 이에 대하여 log를 취하여 다음과 같은 posterior를 최대화하는 MAP estimation을 할 수 있을 것이다.
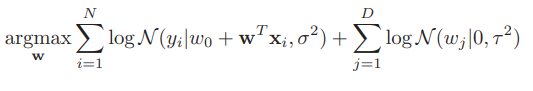
이를 식으로 정리하면, 다음과 같이 표현할 수 있다.
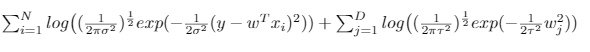
이는 결국 정리하면, 다음 식을 minimization하는 것과 똑같을 것이다.
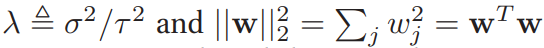
이제서야 우리가 알고 있는 Ridge regression의 식이 나왔다. 이를 minimization하는 것이 Ridge regression인 것이다. 이를 만족하는, 즉 위 식을 minimize하는 최적의 w를 구하면 다음과 같은 식으로 표현할 수 있다. (미분 과정은 생략한다.)

이번 포스팅에서는 Ridge regression이 무엇인지, 그리고 Ridge regression의 형태가 왜 그렇게 나오는지에 대해 수학적으로 증명을 해 보았다. 최대한 쉽게 쓰려고 노력했다. Ridge regression의 형태만 외워서 사용하던 사람들에게 도움이 되었으면 좋겠다 ㅎㅎ
References
Machine Learning: A Probabilitstic Perspective (Adaptive Computation and Machine Learning Series) by Kevin P. Murphy (Author). Chapter 7.








최근댓글